Iceberg+Spark+Trino:區塊鏈現代化開源資料堆疊
在本章中,你將深入了解 Footprint 的關鍵架構更新、主要特色功能,以及其在資料收集與整理層面的表現。
現代區塊鏈資料堆疊面臨的挑戰
現代區塊鏈索引新創公司普遍面臨多項挑戰,包括:
- 龐大的資料量。隨著區塊鏈上的資料持續成長,資料索引必須擴充以因應更高的負載並維持高效率存取,這也導致儲存成本上升、指標計算變慢,以及資料庫伺服器負載增加。
- 複雜的資料處理流程。區塊鏈技術本身極為複雜,建構完整且可靠的資料索引需要深入理解底層資料結構與演算法,同時也受到各種區塊鏈實作方案的影響。例如,以太坊上的 NFT 通常是以 ERC721 或 ERC1155 格式的智能合約建立,而 Polkadot 上的 NFT 則多直接於區塊鏈運行時建構。不論技術細節,最終皆應視為 NFT 並以一致方式保存。
- 整合能力。為了最大化用戶價值,區塊鏈索引解決方案往往必須與其他系統(如分析平台或 API)整合,這在架構設計上需要投入大量心力。
隨著區塊鏈技術日益普及,儲存在鏈上的資料量也不斷增加。這是因為使用者規模擴大,每筆交易都會為區塊鏈新增資料。此外,區塊鏈應用已從單純的貨幣轉移(例如比特幣)拓展至在智能合約中實現商業邏輯的複雜應用。這些智能合約產生大量資料,使區塊鏈結構更為複雜且規模日益龐大。
本文將分階段回顧 Footprint Analytics 技術架構的演進,並以此為例,探討 Iceberg-Trino 技術堆疊如何因應鏈上資料的挑戰。
Footprint Analytics 已將約 22 條公鏈資料、17 個 NFT 市場、1,900 個 GameFi 專案及超過 10 萬個 NFT 收藏索引至語意抽象資料層,成為全球最完整的區塊鏈資料倉儲解決方案。
區塊鏈資料涵蓋超過 200 億筆金融交易紀錄,並經常由資料分析師查詢。
為了因應不斷成長的業務需求,過去數月我們完成了 3 次重大升級,包括:
架構 1.0 Bigquery
Footprint Analytics 創立初期,我們採用 Google Bigquery 作為儲存與查詢引擎。Bigquery 具備優異效能、操作簡便,並提供動態算術能力與彈性 UDF 語法,協助我們高效率完成工作。
但 Bigquery 也存在一些問題:
- 資料未壓縮,導致儲存成本居高不下,特別是儲存 Footprint Analytics 超過 22 條區塊鏈原始資料時。
- 並發能力有限:Bigquery 僅支援 100 筆查詢同時執行,無法滿足 Footprint Analytics 的高並發需求,難以服務大量分析師及用戶。
- 非開源產品,受限於 Google 單一供應商。
因此,我們決定尋找其他替代架構。
架構 2.0 OLAP
我們開始關注數款熱門 OLAP(線上分析處理)產品。OLAP 最大的優勢在於查詢回應速度,通常能在亞秒內回傳大量資料結果,並支援數千筆查詢同時執行。
我們選擇了 Doris 這款頂尖 OLAP 資料庫。雖然表現不俗,但很快遇到以下問題:
- 截至 2022 年 11 月,尚未支援陣列或 JSON 等資料型別。陣列在部分區塊鏈資料中十分常見,例如 EVM 日誌的 topic 欄位。無法直接計算陣列會影響多項業務指標的計算。
- 對 DBT 與 merge 語法支援有限。這些功能是資料工程師在 ETL/ELT(資料提取-載入-轉換)場景的常見需求,且我們需要更新部分新索引資料。
因此,我們無法在生產環境中完全採用 Doris 作為整體資料流程,只能將 Doris 作為 OLAP 資料庫,解決部分資料生產流程問題,並作為查詢引擎提供高速且高並發的查詢能力。
然而,我們無法以 Doris 取代 Bigquery,必須定期將資料從 Bigquery 同步至 Doris,僅將 Doris 作為查詢引擎。這個同步過程也存在諸多問題,例如當 OLAP 引擎忙於前端查詢時,資料寫入會快速累積,導致寫入速度受影響、同步時間拉長,甚至有時無法完成。
我們意識到 OLAP 雖能解決部分問題,但無法成為 Footprint Analytics 的一站式解決方案,尤其在資料處理流程方面。我們面臨的問題更大、更複雜,僅以 OLAP 作為查詢引擎遠遠不夠。
架構 3.0 Iceberg + Trino
Footprint Analytics 架構 3.0 正式登場,這是底層架構的全面重構。我們從零開始設計,將資料儲存、運算與查詢分為三大獨立部分,並汲取 Footprint Analytics 早期架構的經驗,同時參考 Uber、Netflix、Databricks 等大型數據專案的成功案例。
資料湖的導入
我們首先將重心放在資料湖,這是一種適用於結構化及非結構化資料的新型儲存方式。資料湖非常適合存放鏈上資料,因為鏈上資料格式多元,涵蓋非結構化原始資料以及 Footprint Analytics 著名的結構化抽象資料。藉由資料湖,我們期望能解決資料儲存問題,並支援 Spark、Flink 等主流運算引擎,未來 Footprint Analytics 成長時,整合不同型態處理引擎不會產生額外障礙。
Iceberg 能與 Spark、Flink、Trino 及其他運算引擎高度整合,讓我們可針對每項指標選擇最合適的運算方式。例如:
- 複雜運算邏輯指標首選 Spark。
- Flink 適合即時運算。
- 簡易 SQL 執行的 ETL 任務則採用 Trino。
查詢引擎
Iceberg 解決了儲存與運算問題,接下來需考慮查詢引擎的選擇。可選方案有限,主要包括:
- Trino:SQL 查詢引擎
- Presto:SQL 查詢引擎
- Kyuubi:無伺服器 Spark SQL
在深入研究之前,我們最重視的是未來查詢引擎必須與現有架構相容。
- 支援 Bigquery 作為資料來源
- 支援 DBT(我們仰賴它產生多項指標)
- 支援 BI(商業智慧)工具 Metabase
基於上述考量,我們選擇了 Trino。Trino 對 Iceberg 支援度高,開發團隊回應極快,我們回報的 bug 隔天即修復,並於次週釋出新版。對於需要高度回應能力的 Footprint 團隊來說,這無疑是最佳選擇。
效能測試
方向確定後,我們便針對 Trino+Iceberg 組合進行效能測試,檢驗其是否符合理想需求。令人驚訝的是,其查詢速度極快。
多年來,Presto+Hive 一直被認為是 OLAP 領域效能最差的組合,但 Trino+Iceberg 完全顛覆了我們的認知。
我們的測試結果如下:
範例 1:連接大型資料集
將一個 800 GB 的表 1 與另一個 50 GB 的表 2 連接,並執行複雜業務運算。範例 2:大表單執行非重複查詢
測試用 SQL:從表中依日期分組選取不同地址

Trino+Iceberg 組合在相同配置下,速度約為 Doris 的 3 倍。
此外,Iceberg 可採用 Parquet、ORC 等資料格式進行壓縮儲存。Iceberg 表格儲存空間僅為其他資料倉儲的約 1/5,三款資料庫相同表格的儲存大小如下:

註:上述測試皆為實際生產案例,僅供參考。
升級成效
效能測試報告證明我們具備足夠性能,團隊因此花了約 2 個月完成遷移。以下為升級後的架構圖:
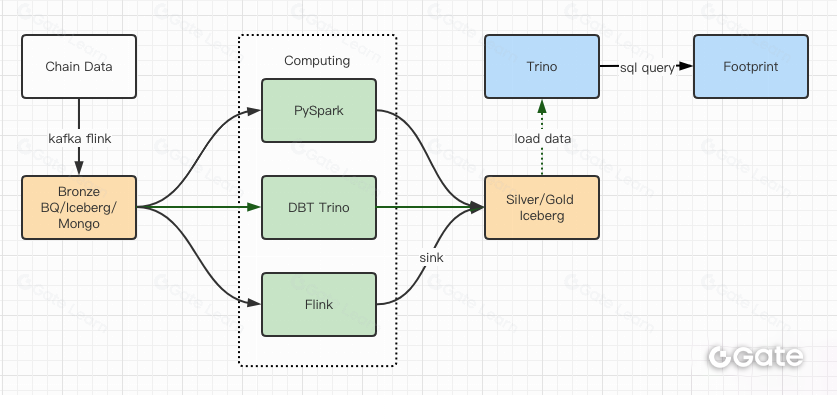
- 多種運算引擎滿足各式業務需求。
- Trino 支援 DBT,可直接查詢 Iceberg,無需再處理資料同步。
- Trino+Iceberg 的卓越效能讓我們能向用戶開放所有原始資料。
小結
自 2021 年 8 月推出以來,Footprint Analytics 團隊在不到一年半內完成三次架構升級,這歸功於團隊致力於為加密貨幣用戶帶來頂尖資料庫技術優勢的渴望與決心,以及在底層基礎設施與架構升級上的卓越表現。
Footprint Analytics 架構 3.0 升級為用戶帶來嶄新體驗,讓不同背景的使用者能深入探索多元用途及場景:
- Footprint 以 Metabase BI 工具建構,協助分析師存取解碼的鏈上資料,自由選擇工具(無需程式碼或硬編碼)進行探索、查詢完整歷史紀錄、交叉比對資料集,及時獲得深入分析。
- 鏈上與鏈下資料可整合至 Web2+Web3 分析。
- 分析師或開發者可在 Footprint 業務抽象基礎上建立/查詢指標,節省 80% 重複資料處理時間,專注於具業務意義的指標、研究及產品解決方案。
- 從 Footprint Web 到 REST API 呼叫皆可無縫體驗,且全以 SQL 為基礎。
- 即時警示及可行性通知提供關鍵訊號,支援投資決策。
相關課程

加密貨幣領域的身份驗證項目概覽

主要加密貨幣衍生品項目概覽

主節點代幣

去中心化身份基礎

加密領域自主研究指南(DYOR)
