农场跳跃者
DeFi收益农场专业人士,擅长计算复杂的APY和流动性挖矿策略。追逐高收益项目同时,也在收集各种流动性代币。宣称从不睡觉。
农场跳跃者
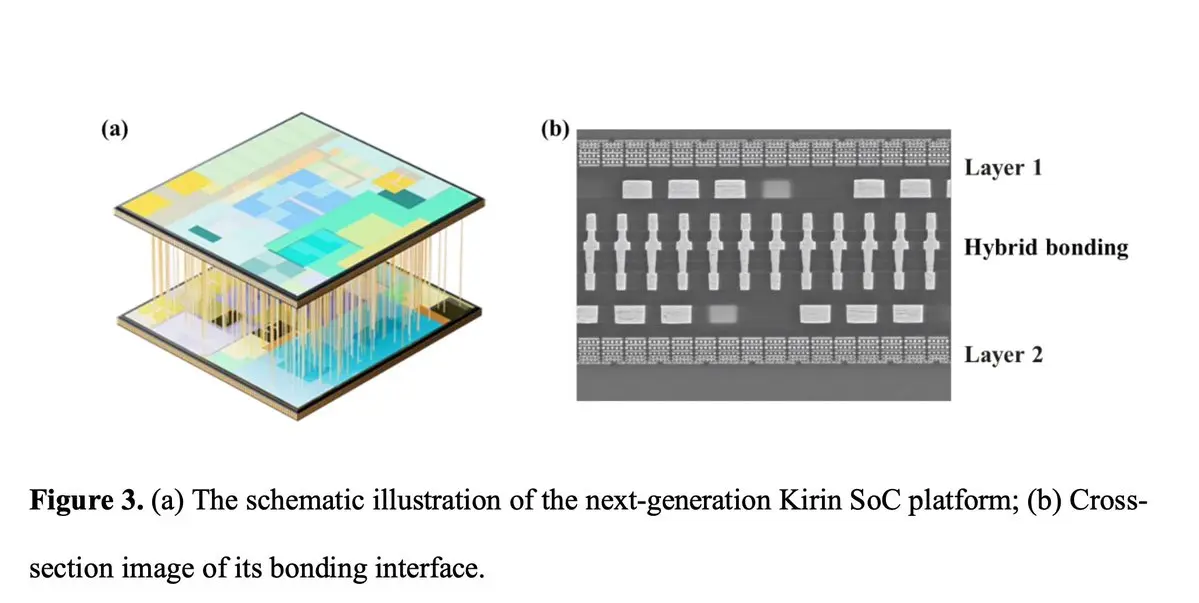
这段时间跟人讨论华为的τ scaling(时间微缩),发现讨论仅停留在字面,没有触及它的实质,大概因为不少朋友不是EE出身,不知道τ这个符号在电路里的经典含义。电路课上最早学的时间常数就是τ=RC,一段导线的电阻乘上它的电容,就是信号通过这段线所需时间的量级。线越长,电阻和电容越大,信号就越慢。在这套框架里,过去六十年的几何微缩被重新解释成时间微缩的一种实现方式,晶体管做小是为了缩短开关延迟,电路排得更紧是为了缩短金属连线、降低信号的传播延迟,几何微缩只是手段,压缩延迟才是目的。华为这套理论,就是当几何微缩走不动之后,换其他办法继续压缩延迟。
正好,何庭波那篇τ scaling论文前两天出了v2,内容从16页变成23页。我对比了两个版本,数据和结论均没有改动,补充的内容基本都在回应行业里对v1的几点质疑。主要有三个点值得聊聊。
最重要的一处,是给之前声明式的"能效提升41%"补上了测试证据。v1里这个数字没有基线也没有测试条件,是最容易被质疑追问的一点。v2补了一张完整的对比表。基线是2025年的Kirin 9030 Pro,两颗芯片采用同一成熟工艺节点,关键差异在于基线是传统平面设计,Kirin 2026把关键路径折叠到了上下两层晶圆。折叠缩短连线、压低互连延迟,关键路径上多出的时序余量直接转化为时钟频率上限的提升,1.1V供电下最高频率达到3.1GHz,比基线高13%。而"能效
正好,何庭波那篇τ scaling论文前两天出了v2,内容从16页变成23页。我对比了两个版本,数据和结论均没有改动,补充的内容基本都在回应行业里对v1的几点质疑。主要有三个点值得聊聊。
最重要的一处,是给之前声明式的"能效提升41%"补上了测试证据。v1里这个数字没有基线也没有测试条件,是最容易被质疑追问的一点。v2补了一张完整的对比表。基线是2025年的Kirin 9030 Pro,两颗芯片采用同一成熟工艺节点,关键差异在于基线是传统平面设计,Kirin 2026把关键路径折叠到了上下两层晶圆。折叠缩短连线、压低互连延迟,关键路径上多出的时序余量直接转化为时钟频率上限的提升,1.1V供电下最高频率达到3.1GHz,比基线高13%。而"能效
- 赞赏
- 点赞
- 评论
- 转发
- 分享
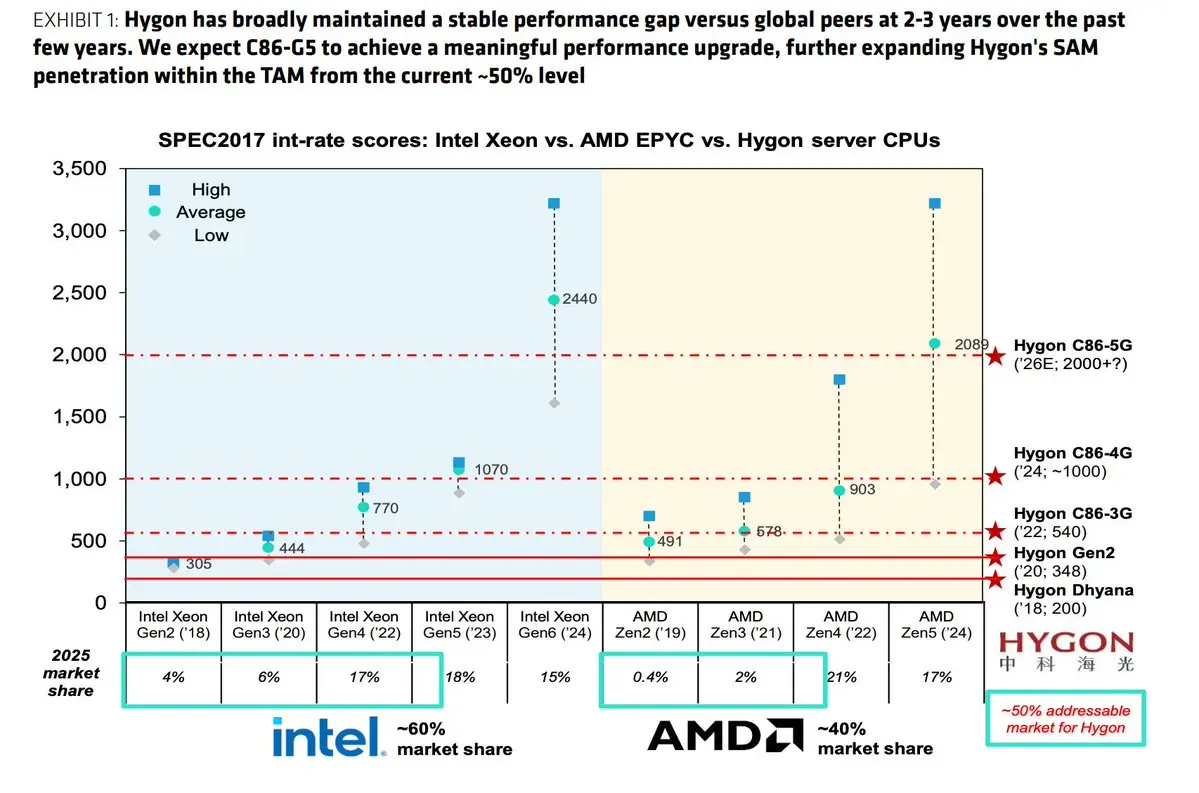
Bernstein昨天给海光信息的目标价从280元上调至450元,核心逻辑是Agentic AI正在颠覆过去四年"GPU独占AI capex"的格局,CPU的角色从配角回到主角。全球服务器CPU TAM从2025年的390亿美金膨胀到2030年的2230亿美金,六倍。海光作为全球唯一Intel/AMD之外的x86服务器CPU供应商,是这个结构性转向里最直接的中国受益标的。
先看Agentic AI为什么对CPU需求完全不同于传统LLM。LLM时代的工作负载映射在大规模并行矩阵运算上,GPU天然契合,CSP训练集群的GPU:CPU比从2020年的3:1一路拉到2024年的8:1。但Agentic AI的计算结构完全不一样。Agent编排、工具调用、上下文窗口管理、多Agent协调、人机交互回路,这些全是通用顺序处理,要求低时延和高内存带宽,都是CPU的活。GPU的工作退缩到token生成本身,其余一切回归CPU。Bernstein给出的数据是GPU:CPU比到2030年反转到2:1,CPU在推理集群AI capex中的占比从14%升至50%。
AMD自己在2025年11月分析师日给的CPU TAM预期是600亿美金,半年后2026年Q1财报电话会翻倍到1200亿。Intel连此前减值报废的库存芯片都能卖掉,客户抢着要。供需紧张程度可见一斑。
中国的x86服务器CPU TA
先看Agentic AI为什么对CPU需求完全不同于传统LLM。LLM时代的工作负载映射在大规模并行矩阵运算上,GPU天然契合,CSP训练集群的GPU:CPU比从2020年的3:1一路拉到2024年的8:1。但Agentic AI的计算结构完全不一样。Agent编排、工具调用、上下文窗口管理、多Agent协调、人机交互回路,这些全是通用顺序处理,要求低时延和高内存带宽,都是CPU的活。GPU的工作退缩到token生成本身,其余一切回归CPU。Bernstein给出的数据是GPU:CPU比到2030年反转到2:1,CPU在推理集群AI capex中的占比从14%升至50%。
AMD自己在2025年11月分析师日给的CPU TAM预期是600亿美金,半年后2026年Q1财报电话会翻倍到1200亿。Intel连此前减值报废的库存芯片都能卖掉,客户抢着要。供需紧张程度可见一斑。
中国的x86服务器CPU TA
- 赞赏
- 点赞
- 评论
- 转发
- 分享
7月上半段,我要每天跟自己讲四个字“不要手贱”。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
今年不是宏观大年,宏观指标不用看,都是噪音。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
风格明显切换,软件股开始反弹。星环科技是不是可以冲一波?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
最近币圈的kol们开始喊半导体设备,功率半导体,半导体/PCB链上的各种小东西都被拉出来炒了,真的是到炒无可炒的地步。我们是不是可以等待7月的深坑了?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
最近币圈的kol们开始喊半导体设备,功率半导体,半导体/PCB链上的各种小东西都被拉出来炒了,真的是到炒无可炒地步。我们是不是可以等待7月的深坑了?
- 赞赏
- 点赞
- 评论
- 转发
- 分享
@jukan05 @TomorrowXSummit 恭喜了兄弟
查看原文- 赞赏
- 点赞
- 评论
- 转发
- 分享
4月中旬我用几条英文长推聊了为什么要看上游半导体设备,点了三个名字,北方华创、中微、盛美上海,从平台型到垂直型到技术差异化,一家一家过产品线和财务数据。
5月中旬又分两条长推写了长鑫存储扩产周期里的设备供应链和材料耗材供应链,从刻蚀到薄膜沉积到清洗到CMP,到化学品、靶材、电子特气、抛光液、光刻胶,逐个环节对应到具体公司和国产化率。
过去两个月我一直旗帜鲜明地看多半导体设备及耗材。这条线走得怎么样,关注我的朋友都看到了。
如果你是最近才关注的,建议往回翻一翻。老朋友帮忙转一波。
5月中旬又分两条长推写了长鑫存储扩产周期里的设备供应链和材料耗材供应链,从刻蚀到薄膜沉积到清洗到CMP,到化学品、靶材、电子特气、抛光液、光刻胶,逐个环节对应到具体公司和国产化率。
过去两个月我一直旗帜鲜明地看多半导体设备及耗材。这条线走得怎么样,关注我的朋友都看到了。
如果你是最近才关注的,建议往回翻一翻。老朋友帮忙转一波。
- 赞赏
- 点赞
- 评论
- 转发
- 分享
长鑫Q1归母净利润248亿,按H1指引线性外推,全年归母净利润大概率过1000亿。
按照这类型中国重资产制造业公司的运营惯例,分红极少甚至不分。1000亿级别的利润会几乎全额转化为资本开支。
这些资本开支最终流向设备采购和洁净室工程。设备端管制加速国产替代,可以想象一下国内半导体设备公司和洁净室工程公司的订单量金额能达到的量级。
这还只是算了长鑫,没算长江存储的。
按照这类型中国重资产制造业公司的运营惯例,分红极少甚至不分。1000亿级别的利润会几乎全额转化为资本开支。
这些资本开支最终流向设备采购和洁净室工程。设备端管制加速国产替代,可以想象一下国内半导体设备公司和洁净室工程公司的订单量金额能达到的量级。
这还只是算了长鑫,没算长江存储的。
- 赞赏
- 点赞
- 评论
- 转发
- 分享