
ИИ-система памяти MemPalace, в разработке которой участвовала Мила Джовович, заявляет, что тесты прошли на максимальный балл и стала вирусной, однако сообщество вскоре разоблачило предполагаемое жульничество в тестировании и ввод в заблуждение данными. Проверка в реальных условиях показала, что эффект преувеличен и в системе обнаружено множество ошибок. Команда признала недостатки и уже работает над их исправлением.
Мила Джовович создала AI-памятный дворец, что привлекло внимание внешнего мира
Вчера (4/7) у AI-сообщества было большое событие: голливудская актриса Мила Джовович (Milla Jovovich), известная по «Обители зла» и «Пятому элементу», вместе с разработчиком Ben Sigman при поддержке Claude Code разработала «MemPalace» — open-source систему AI-памяти.
В тот же момент широко распространилось утверждение о том, что «голливудская звезда в кроссовере сделала проект на идеальный балл». На данный момент MemPalace на GitHub также набрала более 20 000 звезд, но очень быстро это вызвало сомнения в среде разработчиков: есть ли там реальный потенциал или это пиар?
Сначала разберём мотивацию появления MemPalace. Официальная документация утверждает, что система должна решить проблему: содержимое диалога пользователей с AI, процессы принятия решений и обсуждения архитектуры обычно исчезают после завершения рабочих сессий, из-за чего месяцы труда в итоге сводятся к нулю.
Чтобы решить эту проблему, MemPalace использует пространственную архитектуру для хранения памяти: информация явно группируется в «крылья» для персонала или проектов, а также в структуру разных уровней — коридоры, комнаты и ящики — с сохранением текста диалогов для последующего семантического поиска.
Команда разработчиков заявляет, что MemPalace получила 100% идеальный результат в эталонной оценке долгосрочной памяти LongMemEval и, не вызывая никаких внешних API, достигла точности 96,6%, а также может полностью работать локально, не требуя подписки на облачные сервисы, и дополнительно оснащена диалектной системой AAAK, которая, как утверждается, обеспечивает 30-кратное без потерь сжатие.
Источник изображения: GitHub Голливудская звезда Мила Джовович создает AI-дворец памяти, что привлекло внимание внешнего мира
Коллеги и сообщество ставят под сомнение, тестовая методика и рекламные недостатки
Однако заявленный результат MemPalace на 100% в LongMemEval очень быстро вызвал сомнения у коллег.
PenfieldLabs, которая тоже разрабатывает AI-системы памяти, указывает, что MemPalace якобы получила максимальный балл в датасете LoCoMo, что математически невозможно, потому что стандартные ответы в самом этом датасете содержат 99 ошибок.
Анализ PenfieldLabs показал: 100% результатов MemPalace получены за счет установки числа обращений (retrieval) на 50 раз, но максимальная глубина этапов диалога в тестовом наборе составляет всего 32 раза. Это означает, что система напрямую обходит стадию retrieval и передает все данные модели для чтения.
Что касается 100% результата в LongMemEval, выяснилось, что команда разработчиков допустила ошибки в трех конкретных проблемах, сосредоточенных в тестовой части, и написала для них собственный исправляющий код, что наводит на подозрения относительно читинга в тестовом наборе.

Источник изображения: Reddit Коллега PenfieldLabs указывает, что MemPalace заявляет идеальный результат в датасете LoCoMo, что математически невозможно
Практическая проверка пользователей GitHub: в базе тестов есть элементы введения в заблуждение
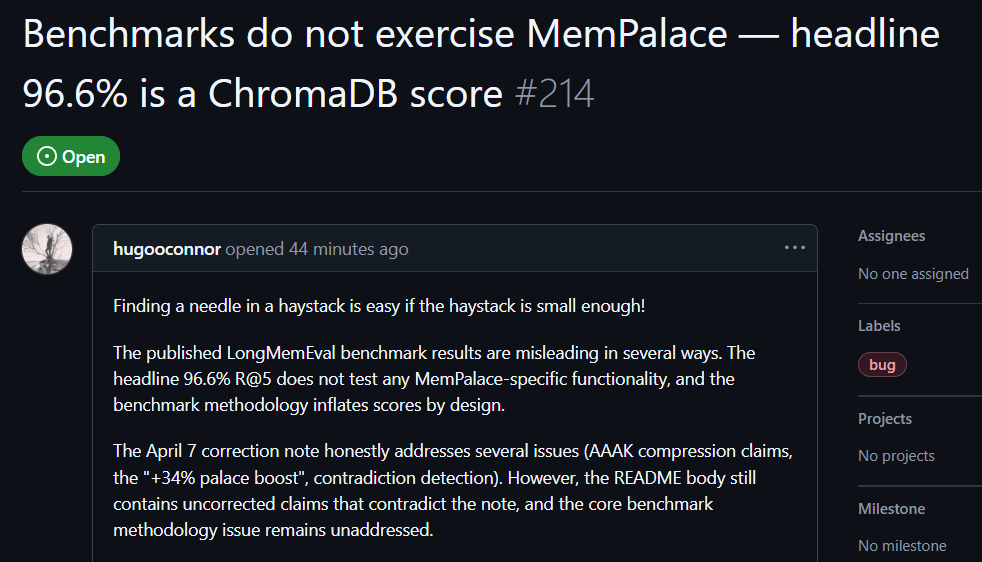
Пользователь GitHub hugooconnor после реальных тестов оставил комментарий: MemPalace заявляет точность retrieval до 96,6%, но на деле она вообще не использует архитектуру «дворца памяти», которую продвигает. hugooconnor утверждает, что их тест просто вызывает стандартную функцию нижележащей базы данных ChromaDB и вообще не задействует какую-либо логическую схему классификации, на которой строится акцент проекта — включая крылья, комнаты или ящики.
После тестирования hugooconnor обнаружил, что когда система действительно включает собственную логику классификации этих «дворцов памяти», результаты retrieval, наоборот, ухудшаются. Например, в режиме комнаты точность падает до 89,4%, а при включении технологии сжатия AAAK точность снижается еще сильнее — до 84,2%; и в обоих случаях оба результата ниже, чем у поведения по умолчанию в стандартной базе данных.
hugooconnor также раскритиковал методику тестирования: тестовая среда MemPalace намеренно сужает область retrieval для каждого вопроса примерно до 50 стадий диалога, и искать ответы в крайне небольшой выборке слишком просто.
Если расширить область до более чем 19 000 стадий диалога в реальных сценариях, точность традиционного поиска по ключевым словам падает до 30%, показывая, что текущая методика тестирования MemPalace скрывает реальную сложность поиска.
Источник изображения: GitHub Практическая проверка пользователей GitHub: в базовом тестировании MemPalace есть элементы введения в заблуждение
При этом, хотя команда разработчиков уже опубликовала исправляющее заявление и признала, что технология AAAK действительно проверена как сжатие с потерями, а также пообещала скорректировать документацию и дизайн системы в соответствии с жесткой критикой со стороны сообщества, основное пояснительное описание проекта по-прежнему сохраняет множество преувеличенных формулировок без исправлений. В частности, упоминаются «30-кратное без потерь сжатие» и «повышение retrieval на 34%», а сравнительные графики с другими конкурентами также полностью лишены ссылок на источники.
Исходный код MemPalace сталкивается с множеством Bug
По мере того как все больше разработчиков загружают тесты, на платформе GitHub появляется множество сообщений о Bug в исходном коде MemPalace.
Пользователь cktang88 перечислил множество серьезных недостатков, включая то, что сжатые команды не работают и приводят к падению системы, ошибку в логике подсчета количества слов в сводке, некорректные статистические данные по «рытью» комнат, а также ситуацию, когда сервер при каждом вызове загружает в память все интерпретационные данные, создавая серьезные проблемы с расходом ресурсов.
Среди прочих указанных проблем также отмечается, что система жестко записывает имена членов семьи разработчика в файл настроек по умолчанию, а при проверке статуса существует принудительно заданный верхний предел отображения для 10 000 записей данных.
Для решения этих проблем открытое сообщество уже начало активно исправлять. Пользователь adv3nt3 отправил множество** запросов на исправление****, включая исправление статистики добычи, удаление заданного по умолчанию имени члена семьи и отсрочку времени инициализации знаний в графе знаний.** Позже и команда разработчиков признала эти ошибки и сейчас, благодаря сотрудничеству с сообществом, постепенно решает проблемы в коде.
Vibe Coding Милы Джовович — круто, а способ маркетинга — не очень
По проекту MemPalace один из пользователей Hacker News darkhanakh сделал такой вывод: у MemPalace складывается ощущение, будто это OpenClaw: то есть результаты искусственно подогнанного бенчмарка (benchmark) делают их похожими на идеально выверенные, а затем это упаковывают в маркетинг как какой-то крупный прорыв.
Он считает, что базовые технологии MemPalace, возможно, действительно интересны, но при наличии таких недостатков в методике тестирования и при этом еще продвигают ее со слоганом «самый высокий публичный результат за всю историю», это выглядит не слишком уместно. «Но знаете, то, что Мила Джовович занимается Vibe Coding — я думаю, все равно довольно круто».
Дополнительное чтение:
AI пишет код и попадает в неприятности! В приложении «Ищущий охотник за скоропортом» при магазине всплыла проблема с безопасностью данных, GPS дома полностью обнажается
