O desafio do stack de dados de blockchain moderno
Uma startup moderna de indexação de blockchain enfrenta diversos desafios, como:
- Volumes massivos de dados. Com o crescimento dos dados na blockchain, o índice precisa escalar para lidar com a carga crescente e garantir acesso eficiente. Isso resulta em custos de armazenamento mais altos, cálculos de métricas mais lentos e maior carga no servidor de banco de dados.
- Pipelines de processamento de dados complexos. Blockchain é uma tecnologia complexa, e criar um índice de dados confiável exige profundo conhecimento das estruturas e algoritmos subjacentes. A diversidade das implementações de blockchain amplia esse desafio. Por exemplo, NFTs em Ethereum geralmente são criados em smart contracts seguindo os padrões ERC721 e ERC1155, enquanto em Polkadot, por exemplo, a implementação costuma ser feita diretamente no runtime da blockchain. No fim, todos são NFTs e precisam ser tratados como tal.
- Capacidade de integração. Para maximizar o valor entregue ao usuário, a solução de indexação pode precisar integrar o índice a outras plataformas, como ferramentas de analytics ou APIs. Isso é desafiador e exige um projeto arquitetônico robusto.
Com a adoção crescente da tecnologia blockchain, o volume de dados armazenados aumentou. Isso ocorre porque mais usuários aderem à tecnologia e cada transação adiciona novos dados. Além disso, o uso da blockchain evoluiu de simples transferências financeiras, como no Bitcoin, para aplicações complexas que implementam lógica de negócios em smart contracts. Esses contratos inteligentes geram grandes volumes de dados, aumentando a complexidade e o tamanho da blockchain. Com o tempo, isso resultou em blockchains cada vez maiores e mais complexas.
Neste artigo, analisamos a evolução da arquitetura tecnológica da Footprint Analytics, em etapas, como um estudo de caso para explorar como o stack Iceberg-Trino enfrenta os desafios dos dados on-chain.
A Footprint Analytics já indexou cerca de 22 blockchains públicas, 17 marketplaces de NFT, 1.900 projetos GameFi e mais de 100.000 coleções de NFT em uma camada semântica de abstração de dados. Trata-se da solução de data warehouse de blockchain mais abrangente do mundo.
Os dados de blockchain, que incluem mais de 20 bilhões de linhas de registros de transações financeiras frequentemente consultados por analistas, são diferentes dos logs de ingresso dos data warehouses tradicionais.
Nos últimos meses, passamos por três grandes atualizações para atender às crescentes demandas de negócios:
Arquitetura 1.0 Bigquery
No início da Footprint Analytics, utilizávamos o Google Bigquery como nosso mecanismo de armazenamento e consulta. O Bigquery é extremamente rápido, fácil de usar e oferece poder computacional dinâmico e uma sintaxe UDF flexível, o que nos ajudava a entregar resultados rapidamente.
No entanto, o Bigquery apresenta algumas limitações.
- Os dados não são compactados, resultando em custos elevados de armazenamento, especialmente ao lidar com dados brutos de mais de 22 blockchains da Footprint Analytics.
- Concorrência limitada: o Bigquery suporta apenas 100 consultas simultâneas, insuficiente para cenários de alta demanda na Footprint Analytics, com muitos analistas e usuários.
- Dependência do Google Bigquery, que é um produto fechado.
Por isso, optamos por explorar outras arquiteturas.
Arquitetura 2.0 OLAP
Ficamos atentos ao surgimento de produtos OLAP que ganharam popularidade. A principal vantagem do OLAP é o tempo de resposta: normalmente, retorna resultados em subsegundos para grandes volumes de dados e suporta milhares de consultas simultâneas.
Escolhemos o Doris, um dos melhores bancos de dados OLAP, para testar. O desempenho foi bom, mas logo surgiram outros desafios:
- Tipos de dados como Array ou JSON ainda não eram suportados (novembro de 2022). Arrays são comuns em algumas blockchains, como o campo topic nos logs EVM. Não conseguir processar Arrays impacta diretamente o cálculo de muitas métricas de negócios.
- Suporte limitado ao DBT e a comandos de merge, essenciais para engenheiros de dados em cenários ETL/ELT que exigem atualização de dados recém-indexados.
Dessa forma, não era possível usar o Doris em todo o pipeline de produção. Tentamos utilizá-lo como banco OLAP para resolver parte do problema, atuando como engine de consulta e fornecendo alto desempenho e concorrência.
Infelizmente, não conseguimos substituir o Bigquery pelo Doris. Precisávamos sincronizar periodicamente os dados do Bigquery para o Doris, limitando o uso deste último apenas como engine de consulta. O processo de sincronização apresentava problemas, como o acúmulo de escritas de atualização quando o OLAP estava ocupado atendendo consultas do front-end. Isso reduzia a velocidade das gravações, prolongava a sincronização e, por vezes, impossibilitava sua conclusão.
Percebemos que o OLAP resolvia alguns gargalos, mas não era a solução definitiva para a Footprint Analytics, especialmente para o pipeline de processamento de dados. Nosso desafio era maior e mais complexo; o OLAP, apenas como engine de consulta, não era suficiente.
Arquitetura 3.0 Iceberg + Trino
Apresentamos a arquitetura 3.0 da Footprint Analytics, uma reformulação completa da base tecnológica. Redesenhamos a arquitetura do zero, separando armazenamento, processamento e consulta de dados em três camadas. Aproveitamos as lições das versões anteriores e de projetos de big data bem-sucedidos como Uber, Netflix e Databricks.
Introdução ao data lake
Voltamos nosso foco ao data lake, um novo modelo de armazenamento para dados estruturados e não estruturados. O data lake é ideal para dados on-chain, já que os formatos variam de dados brutos não estruturados a abstrações estruturadas, como na Footprint Analytics. Esperávamos que o data lake resolvesse o desafio de armazenamento e, idealmente, suportasse engines como Spark e Flink, facilitando a integração com diferentes tipos de processamento à medida que a Footprint Analytics evolui.
O Iceberg integra-se perfeitamente com Spark, Flink, Trino e outros engines, permitindo selecionar o processamento ideal para cada métrica. Por exemplo:
- Para lógica computacional complexa, usamos Spark.
- Para processamento em tempo real, Flink.
- Para tarefas ETL simples via SQL, Trino.
Engine de consulta
Com o Iceberg solucionando armazenamento e processamento, era preciso escolher o engine de consulta. As opções consideradas foram:
- Trino: engine SQL
- Presto: engine SQL
- Kyuubi: Spark SQL serverless
O critério principal era a compatibilidade com a arquitetura atual.
- Suporte ao Bigquery como fonte de dados
- Suporte ao DBT, essencial para produção de métricas
- Suporte à ferramenta de BI Metabase
Diante disso, escolhemos o Trino, que oferece excelente integração com Iceberg e uma equipe extremamente ágil: relatamos um bug, solucionado no dia seguinte e liberado na versão mais recente na semana seguinte. Foi a melhor escolha para a Footprint, que exige alta agilidade na implementação.
Testes de performance
Após definir o caminho, realizamos testes de performance na combinação Trino + Iceberg para avaliar se atenderia às nossas necessidades. Para nossa surpresa, as consultas foram extremamente rápidas.
Sabendo que Presto + Hive sempre foi referência negativa no universo OLAP, a combinação Trino + Iceberg superou todas as expectativas.
Veja os resultados dos testes:
caso 1: join de grandes volumes
Uma tabela de 800 GB faz join com outra de 50 GB e realiza cálculos de negócios complexos
caso 2: consulta distinct em uma grande tabela
SQL de teste: select distinct(address) from table group by day

A combinação Trino+Iceberg foi cerca de 3 vezes mais rápida que o Doris na mesma configuração.
Além disso, o Iceberg pode utilizar formatos como Parquet e ORC, que comprimem e armazenam os dados. O armazenamento de tabelas no Iceberg ocupa cerca de 1/5 do espaço dos outros data warehouses. Veja o tamanho da mesma tabela nos três bancos:

Observação: Os testes acima são exemplos reais de produção e servem apenas como referência.
・Efeito do upgrade
Os relatórios de performance nos deram confiança e, em cerca de dois meses, a equipe concluiu a migração. Veja o diagrama da arquitetura após o upgrade:
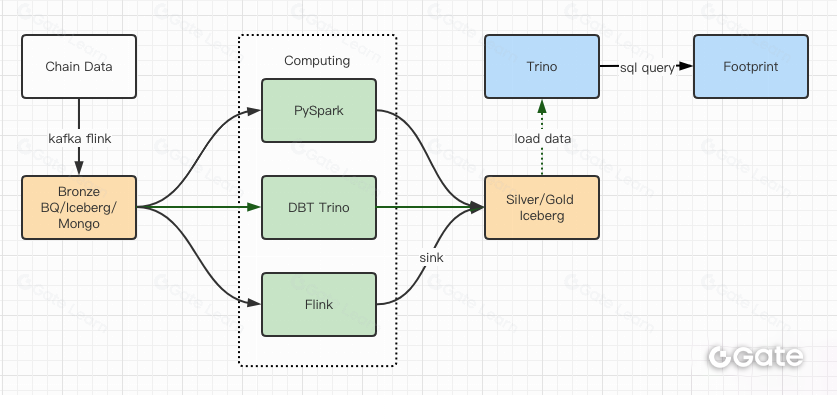
- Múltiplos engines computacionais atendem a diferentes necessidades.
- Trino suporta DBT e consulta o Iceberg diretamente, eliminando a sincronização de dados.
- O desempenho do Trino + Iceberg permite liberar todos os dados Bronze (dados brutos) para os usuários.
Resumo
Desde agosto de 2021, a equipe Footprint Analytics realizou três upgrades arquiteturais em menos de um ano e meio, graças à determinação em levar o melhor da tecnologia de bancos de dados ao público cripto e à execução sólida na implementação e atualização da infraestrutura.
O upgrade arquitetural 3.0 da Footprint Analytics trouxe uma nova experiência aos usuários, permitindo que pessoas de diferentes perfis obtenham insights em usos e aplicações mais diversos:
- Com a ferramenta de BI Metabase, Footprint permite que analistas acessem dados on-chain decodificados, explorem com liberdade (no-code ou hardcode), consultem todo o histórico, cruzem bases e obtenham insights rapidamente.
- Integra dados on-chain e off-chain para análises web2 + web3;
- Ao construir e consultar métricas sobre a abstração de negócios da Footprint, analistas e desenvolvedores economizam tempo em 80% do trabalho repetitivo de processamento de dados e podem focar em métricas relevantes, pesquisa e soluções de produto para seus negócios.
- Experiência fluida do Footprint Web até chamadas REST API, tudo baseado em SQL
- Alertas em tempo real e notificações acionáveis para decisões de investimento