AI request routing is an infrastructure capability used to manage inference resources across multiple models. As large language models such as GPT, Claude, Gemini, and DeepSeek continue to evolve, more AI applications are connecting to multiple models at the same time. Choosing intelligently among different models has become an important issue in AI system design.
Gate.AI sits between applications and model services, serving as both an AI Gateway and a model routing layer. As multi-model architecture gradually becomes an industry trend, model routing affects not only system performance, but also cost control, service stability, and the autonomous operation of AI Agents.
What Is AI Request Routing?
AI request routing is a scheduling mechanism that automatically selects a target model based on task characteristics. In traditional architectures, applications usually call a fixed single model to complete inference tasks. In a multi-model architecture, however, different models have different strengths, such as reasoning, code generation, long text processing, or cost efficiency.
The model routing layer analyzes the request content and sends the request to the model best suited to execute it, improving overall resource utilization.
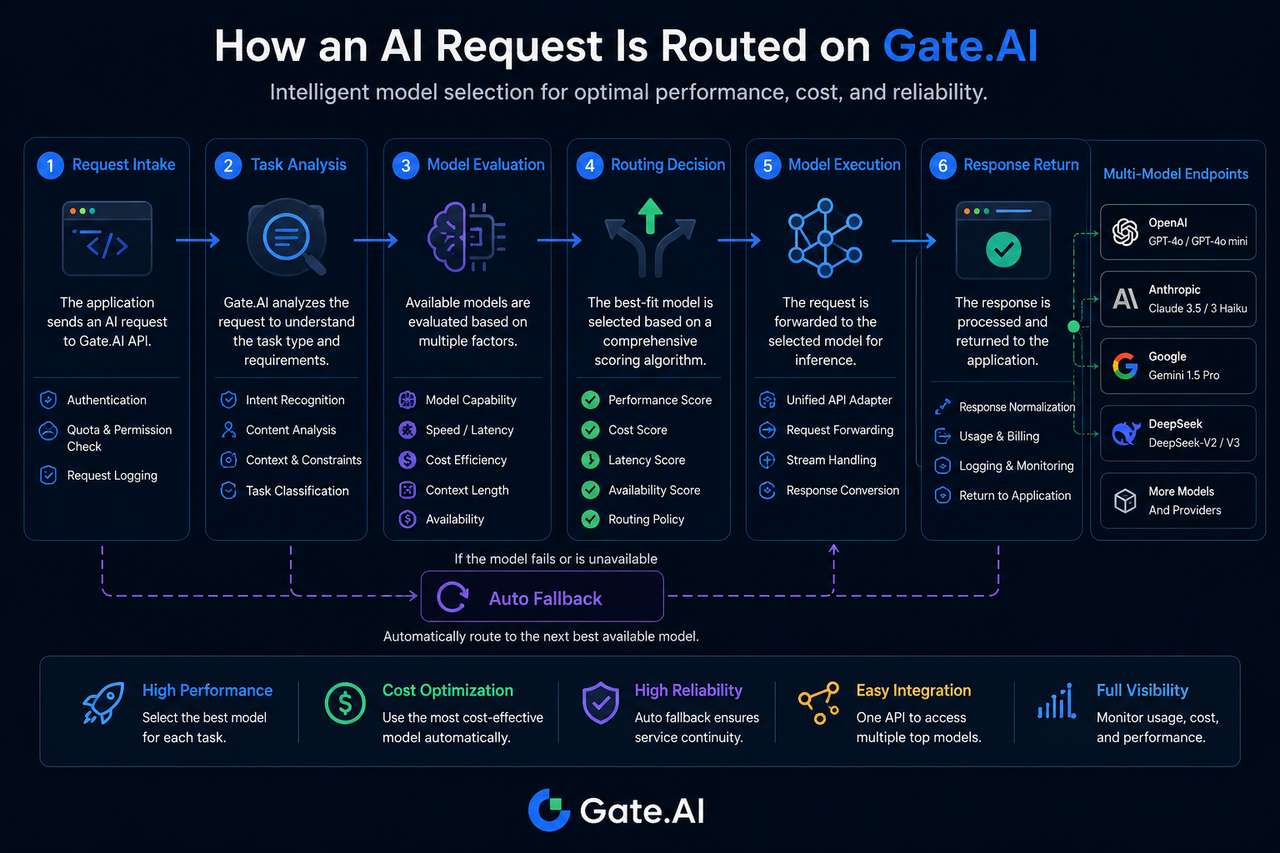
Step 1: The AI Request Enters Gate.AI
A routing workflow begins with request intake.
When an application sends a request, the request first enters the Gate.AI Gateway layer. At this point, the system verifies identity information, checks access permissions, and records request parameters.
The request content usually includes:
After validation is complete, the request moves into the next stage of analysis.
Step 2: The System Analyzes the Task Type
Task identification is a key part of model routing.
Gate.AI determines what type of task the request belongs to based on its characteristics, such as:
-
General conversation
-
Long text summarization
-
Content creation
-
Code generation
-
Data analysis
-
Agent tool calling
Different tasks place clearly different demands on model capabilities.
Accurately identifying the task type helps make the subsequent model matching process more efficient.
Step 3: Model Capability Evaluation and Matching
The model evaluation stage determines the range of candidate models.
The system refers to a model capability database to filter the currently available models.
Common evaluation dimensions include:
-
Reasoning ability
-
Context length
-
Response speed
-
Tool calling capability
-
Multimodal support
-
Cost level
For example, complex reasoning tasks may prioritize models with stronger reasoning ability, while long document processing tasks may be matched first with models that support very long context windows.
Step 4: Generate the Routing Decision
The routing decision stage determines the final model that will execute the request.
After candidate models are identified, the system scores them by combining multiple indicators.
Common reference factors include:
Model performance determines the quality of task completion.
Complex problems usually require stronger logical reasoning, while simple tasks do not necessarily need the highest performance model.
Response Latency
Response speed directly affects the user experience.
For real-time interaction scenarios, low-latency models often receive higher priority.
Calling Cost
Inference costs vary from model to model.
When multiple models can complete the same task, the system may prioritize the model with higher resource efficiency.
Service Availability
Model status is also an important basis for routing decisions.
If a model experiences rate limiting, failure, or congestion, the system automatically lowers its priority.
Step 5: The Request Is Sent to the Target Model
After the routing decision is complete, the request is forwarded to the target model.
At this stage, Gate.AI handles interface differences among different model providers in a unified way.
For application developers, there is no need to build separate interfaces for different models.
A unified access layer reduces development complexity and improves system scalability.
Step 6: The Model Generates and Returns the Result
After the target model completes inference, it returns the result to Gate.AI.
Gate.AI standardizes the response so that data structures returned by different models remain consistent.
A unified output format reduces adaptation work at the application layer and simplifies later system integration.
The final result is then returned to the application or AI Agent.
What Happens When the Target Model Is Unavailable?
Model unavailability is common in multi-model ecosystems.
If the target model times out, is rate limited, or encounters a service exception, Gate.AI can trigger an automatic fallback process.
The system reselects a backup model according to preset policies and continues executing the task.
This mechanism reduces the risk of single points of failure and improves overall service continuity.
For more on this workflow, see “What Happens When an AI Model Fails? A Complete Look at Gate.AI’s Automatic Fallback Mechanism.”
Example of an AI Request Routing Workflow
The following example shows a typical workflow for a content generation task:
| Stage |
System Action |
| Request intake |
The application sends a generation request |
| Task analysis |
Identified as long-form content creation |
| Model filtering |
Selects candidate models that support long context |
| Routing decision |
Scores models based on performance, cost, and latency |
| Model execution |
Sends the request to the target model |
| Result processing |
Returns standardized output |
| Failure recovery |
Automatically switches to a backup model when necessary |
This workflow is usually completed in a very short time, and users often do not notice the model selection process happening behind the scenes.
Conclusion
As one of the core capabilities of an AI Gateway, AI request routing dynamically selects the model best suited to execute a task among multiple large language models. Compared with fixed calls to a single model, model routing makes better use of the strengths of different models while improving system flexibility, stability, and resource utilization.
In Gate.AI’s architecture, an AI request goes through several stages, including request intake, task identification, model evaluation, routing decision, model execution, and result delivery.
FAQs
Why Does Gate.AI Need Model Routing?
Gate.AI connects multiple AI model ecosystems, and different models have their own advantages in reasoning, code generation, long text processing, and other areas. Model routing automatically selects the most suitable model based on task requirements.
Does One AI Request Call Multiple Models at the Same Time?
An AI request is usually executed by a single target model, but in some complex scenarios, a multi-model collaboration mode can also be used, with different models handling different parts of the task.
What Factors Are Mainly Considered in AI Routing Decisions?
AI routing decisions usually consider multiple factors, including model performance, response speed, inference cost, context length, tool calling capability, and service availability.
What Is the Difference Between Model Routing and Load Balancing?
Load balancing mainly addresses traffic distribution, while model routing focuses on matching model capabilities to the task. Model routing selects the most suitable model based on task characteristics, rather than simply spreading request traffic.








