
Autor: Phosphen
编译:Gans 甘斯,Bagel预测市场观察
Este homem reuniu dados de todas as partidas profissionais de ténis dos últimos 43 anos, inseriu-os num modelo de aprendizagem automática e fez uma única pergunta: consegue prever quem vai ganhar?
O modelo respondeu com uma palavra: Sim.
Depois, na Austrália Open deste ano, previu corretamente 99 de 116 jogos, com uma precisão de 85%!
São partidas que o modelo nunca tinha visto durante o treino, e mesmo assim previu o vencedor de cada uma delas, incluindo o campeão final.

Tudo isto com um portátil, dados gratuitos e código de código aberto, criado por @theGreenCoding.
A seguir, vou desmontar este projeto que transforma dados em ouro, desde os dados originais até às previsões finais. Este será um dos exemplos mais impressionantes de IA + previsão bem-sucedida que já viste.
Ponto de partida: uma pasta com dados de ténis de 43 anos
A história começa com um conjunto de dados considerado o “Santo Graal dos Dados Desportivos”.
Este conjunto cobre todas as partidas profissionais de 1985 a 2024, registadas pela ATP (Associação de Ténis Profissional Masculino).
Quebrar pontos de serviço, duplas faltas, forehands, backhands, altura dos jogadores, idade, classificação, históricos de confrontos, tipo de piso… a ATP registou cada detalhe, ponto a ponto.
Quarenta anos de ficheiros CSV, todos numa única pasta.
Quando abriu o conjunto completo, o computador travou.
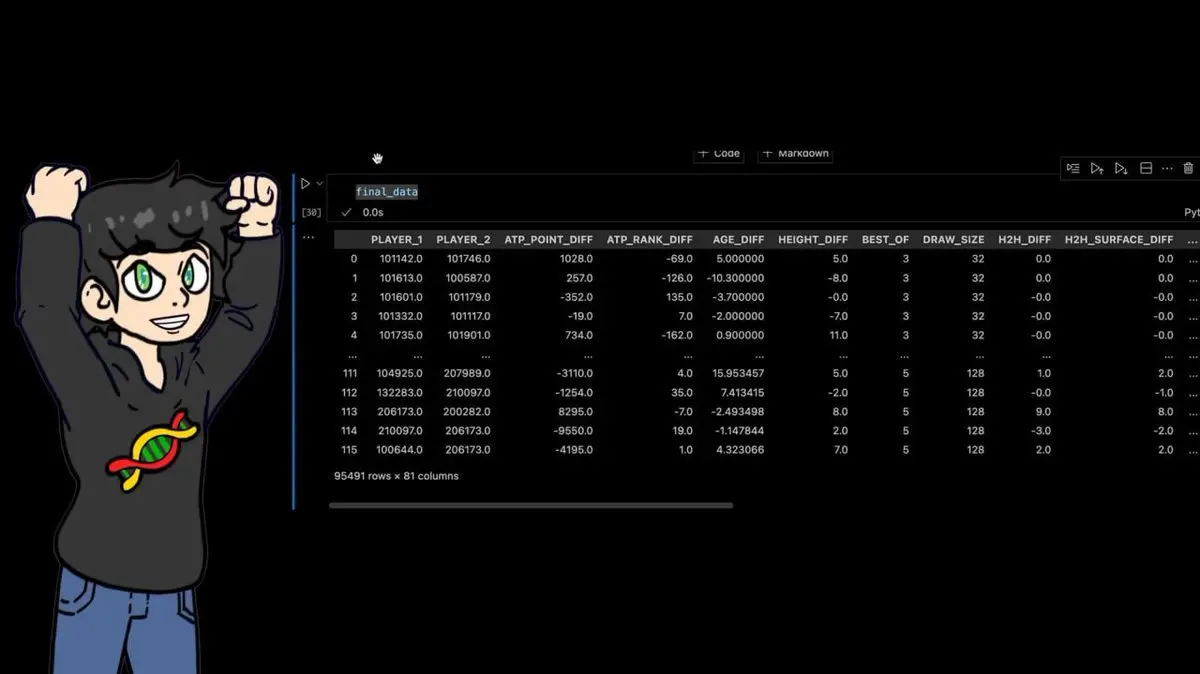
Mas não desistiu. Para as 95.491 partidas do conjunto, calculou ainda muitas características derivadas:
- Histórico de confrontos entre os dois jogadores
- Diferença de idade, de altura
- Percentagens de vitórias nos últimos 10, 25, 50, 100 jogos
- Diferença na taxa de pontos ganhos com o primeiro serviço
- Diferença na taxa de recuperação de break points
- Um sistema de pontuação ELO personalizado, inspirado no xadrez (ponto-chave)
No final, o conjunto tinha: 95.491 linhas × 81 colunas.
Cada partida de ténis profissional dos últimos 40 anos, com dezenas de características calculadas manualmente.
Segundo passo: algoritmo inspirado no Titanic

Antes de inserir os dados no classificador, quis entender bem como o algoritmo funciona. Para isso, escreveu uma árvore de decisão do zero, usando numpy.
A árvore de decisão funciona como um jogo de raciocínio — faz perguntas sequenciais para chegar à resposta.
Para ilustrar, escolheu um conjunto de dados bem diferente: o Titanic.
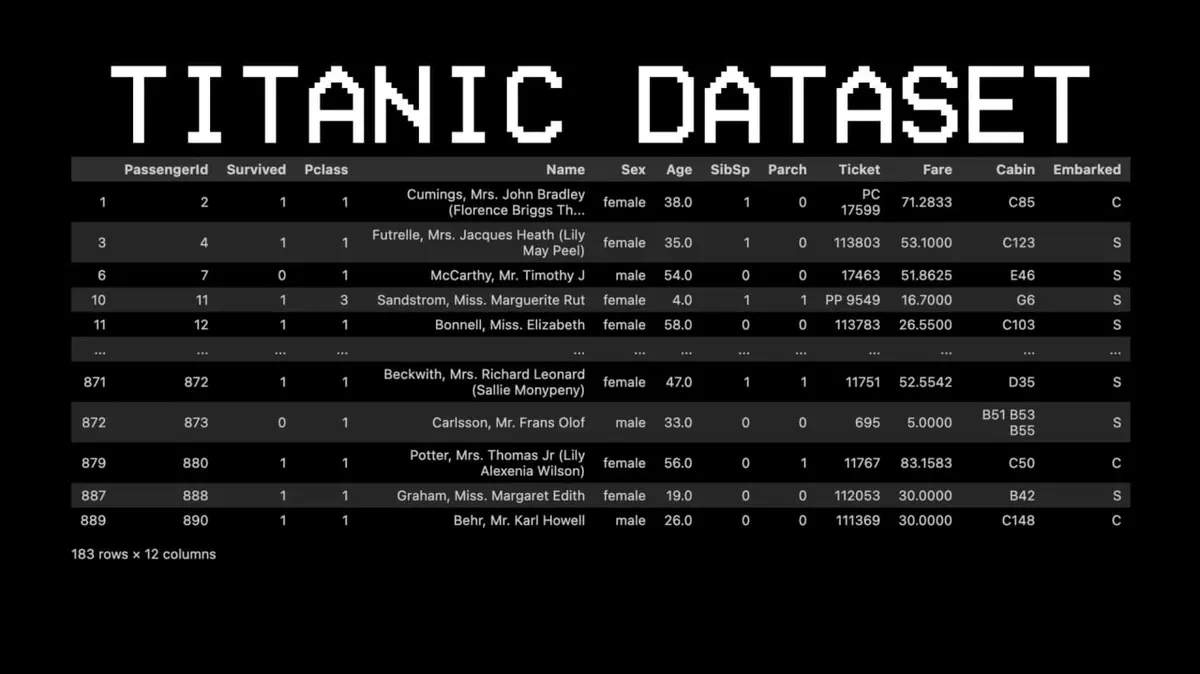
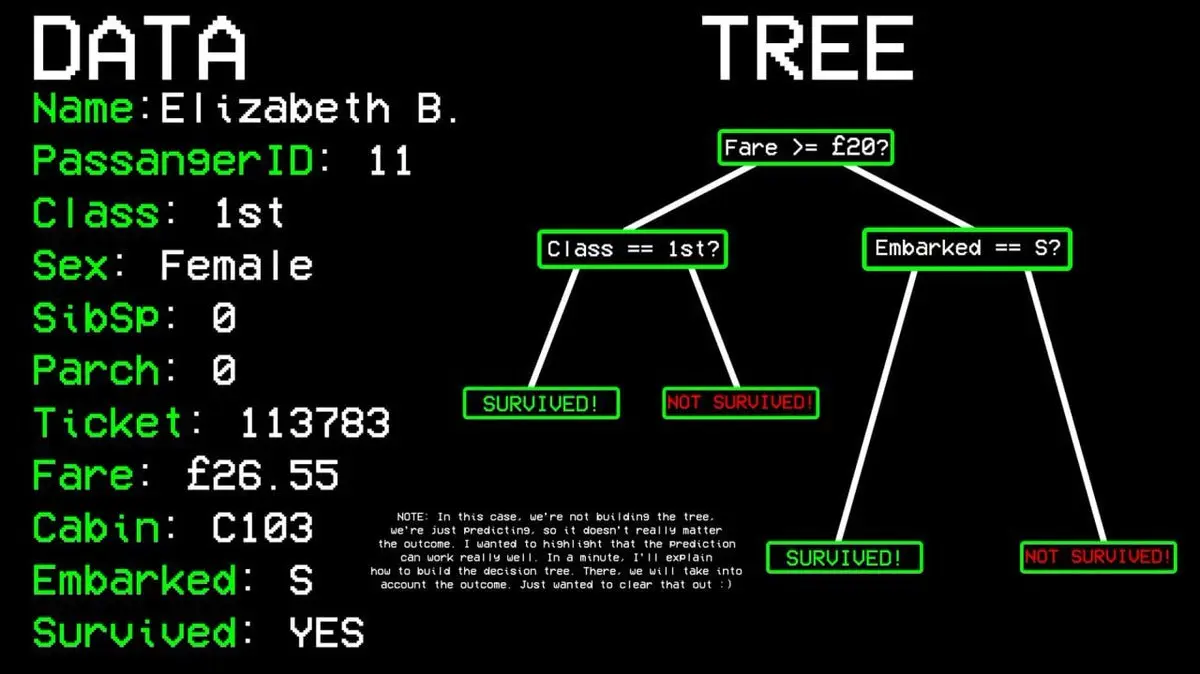
Por exemplo: Sobrevivente do passageiro 11?
- Pergunta 1: Está na primeira classe? → Sim.
- Pergunta 2: É mulher? → Sim.
- Resultado: Sobreviveu.
Como o algoritmo decide quais perguntas fazer?
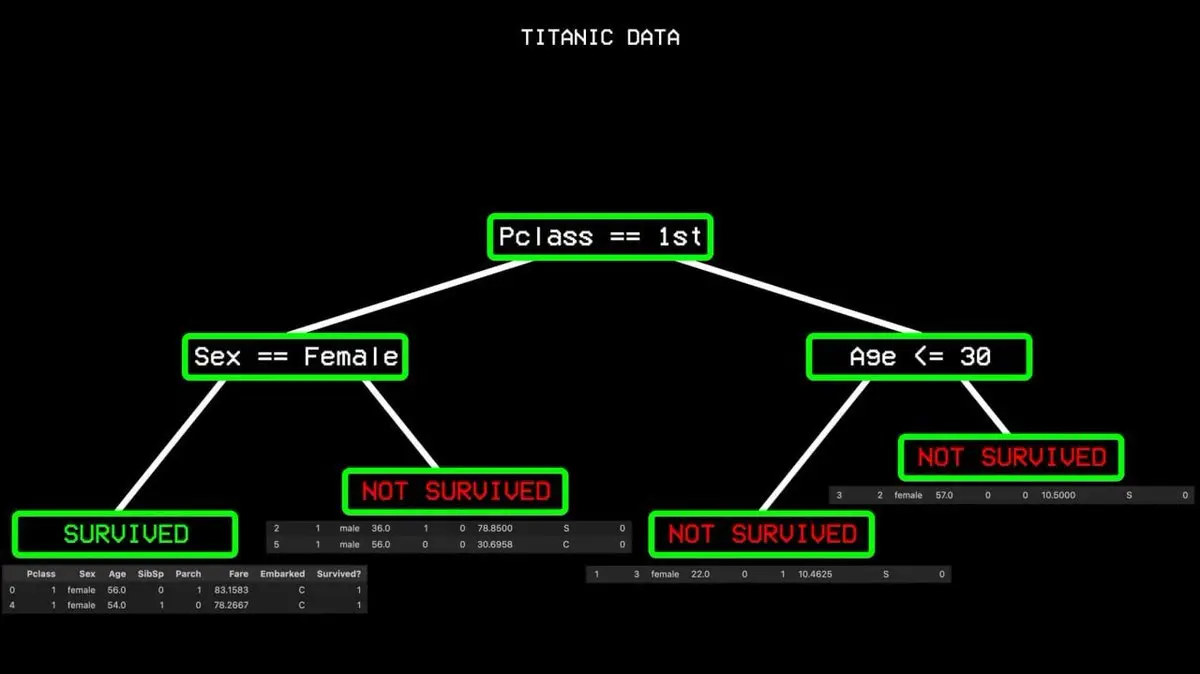
Começa por todos os dados, encontra a variável que melhor separa “sobrevive” de “não sobrevive”. No Titanic, essa variável foi a classe de cabine. Passageiros de primeira classe de um lado, os outros do outro.
Mas há casos de naufrágios de primeira classe, o que gera “impureza”. O algoritmo procura então o próximo melhor ponto de divisão: o género. Todas as mulheres de primeira classe sobreviveram, formando um “nó puro”, e a divisão termina aqui.
Repete esse processo até construir uma árvore de decisão completa, que cobre todas as possibilidades.
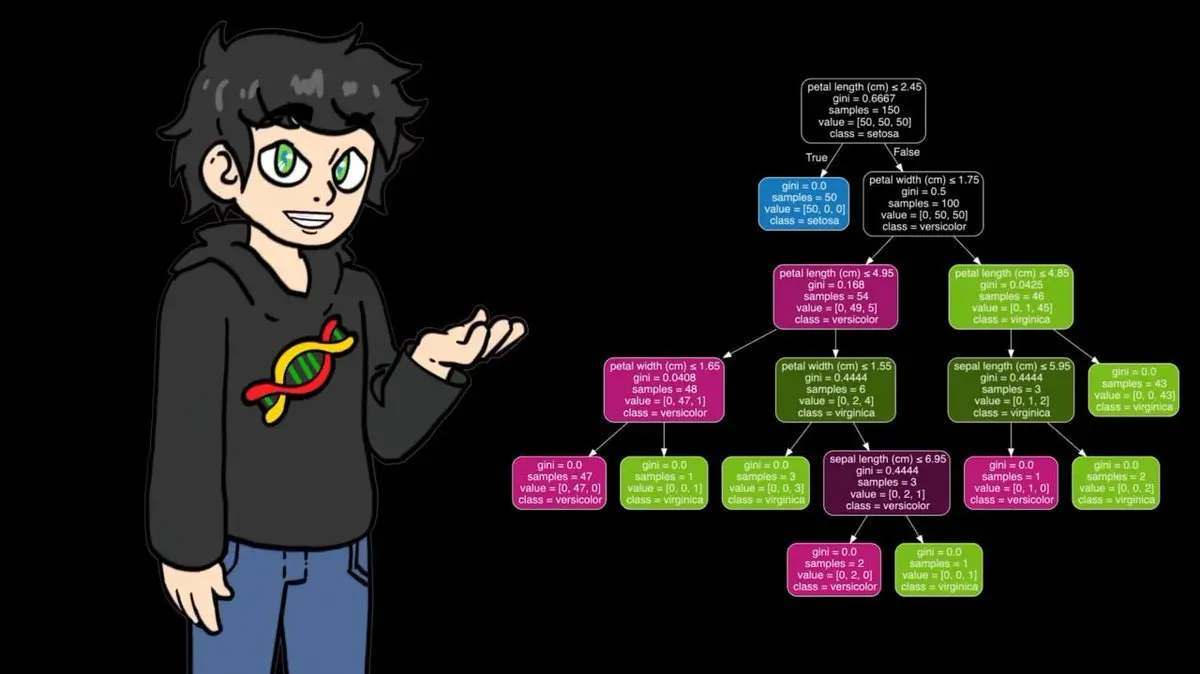
A versão que escreveu com numpy funciona bem com conjuntos pequenos, mas com os 95.000 jogos de ténis, ficou extremamente lento. Por isso, na fase de treino, trocou para a versão otimizada do sklearn, que é igual na lógica, mas muito mais rápida.
Terceiro passo: identificar as variáveis-chave para vencer
Antes de treinar o modelo, criou uma grande matriz de dispersão (pairplot do SNS) com todas as variáveis, para procurar padrões que distinguem vencedores de derrotados.

A maioria das características eram ruído. IDs de jogadores, por exemplo, não servem para nada. A diferença de percentagem de vitórias tinha algum padrão, mas não era clara o suficiente para um classificador confiável.
A única variável que se destacou foi a diferença de pontuação ELO (ELO_DIFF).
O gráfico de dispersão de ELO_DIFF e ELO_SURFACE_DIFF mostrou uma separação clara entre os dois grupos, enquanto as demais variáveis não se comparavam.
Essa descoberta levou à construção do núcleo do projeto.
Quarto passo: aplicar o sistema de pontuação do xadrez ao ténis
ELO é um método de avaliação de nível técnico, usado inicialmente no xadrez. O atual número 1 do mundo, Magnus Carlsen, tem 2833 pontos.

Decidiu aplicar esse sistema ao ténis:
- Cada jogador começa com 1500 pontos
- Vencer aumenta a pontuação; perder diminui
- A quantidade de pontos ganhos ou perdidos depende da diferença de pontuação com o adversário: vencer um de nível mais alto dá mais pontos, perder para um mais fraco tira mais pontos
Usou a final de Wimbledon de 2023 como exemplo: Carlos Alcaraz (2063) contra Novak Djokovic (2120). Alcaraz virou o jogo e venceu.

Calculando com a fórmula: Alcaraz +14 pontos, Djokovic -14 pontos.
Embora simples, ao aplicar aos 43 anos de dados históricos, o poder dessa fórmula é surpreendente.
Quinto passo: visualização do domínio dos “Três Grandes”
Traçou a curva do ELO de Federer ao longo de toda a carreira, desde o início até a aposentadoria, com cada jogo registrado.
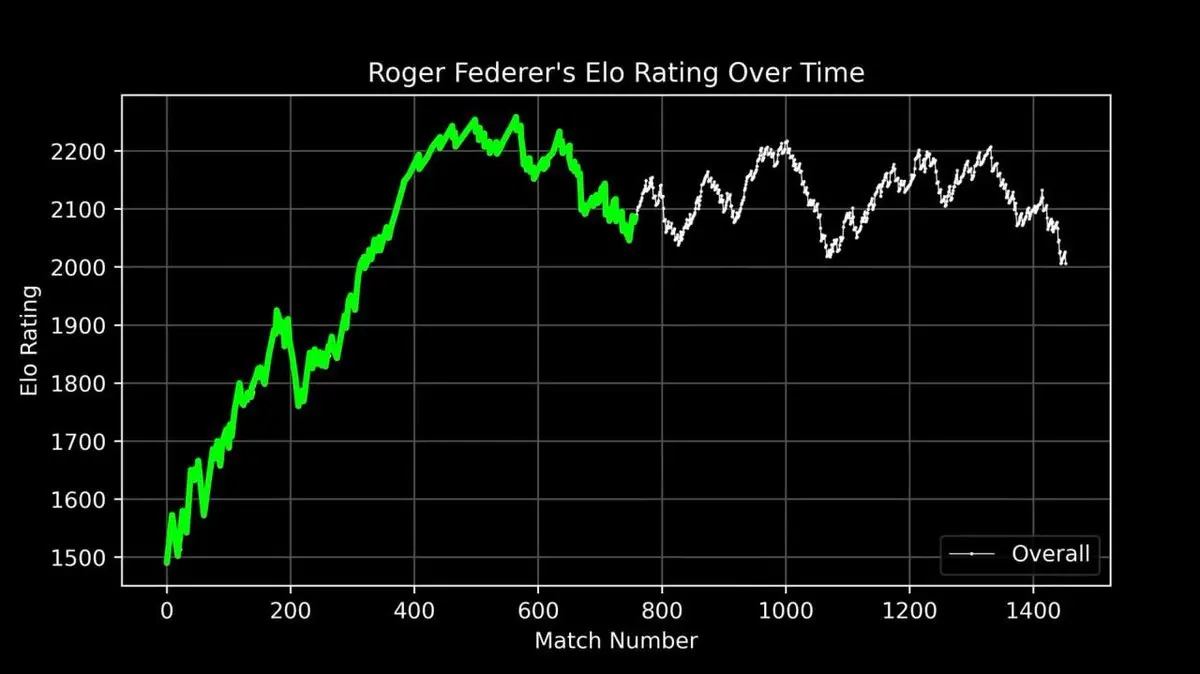
Mostrou toda a trajetória: subida rápida no início, domínio absoluto na fase de pico (cerca da 400ª partida), e oscilações na fase final.
Mas o mais impressionante foi colocar Federer, Nadal e Djokovic no mesmo gráfico, desde 1985:
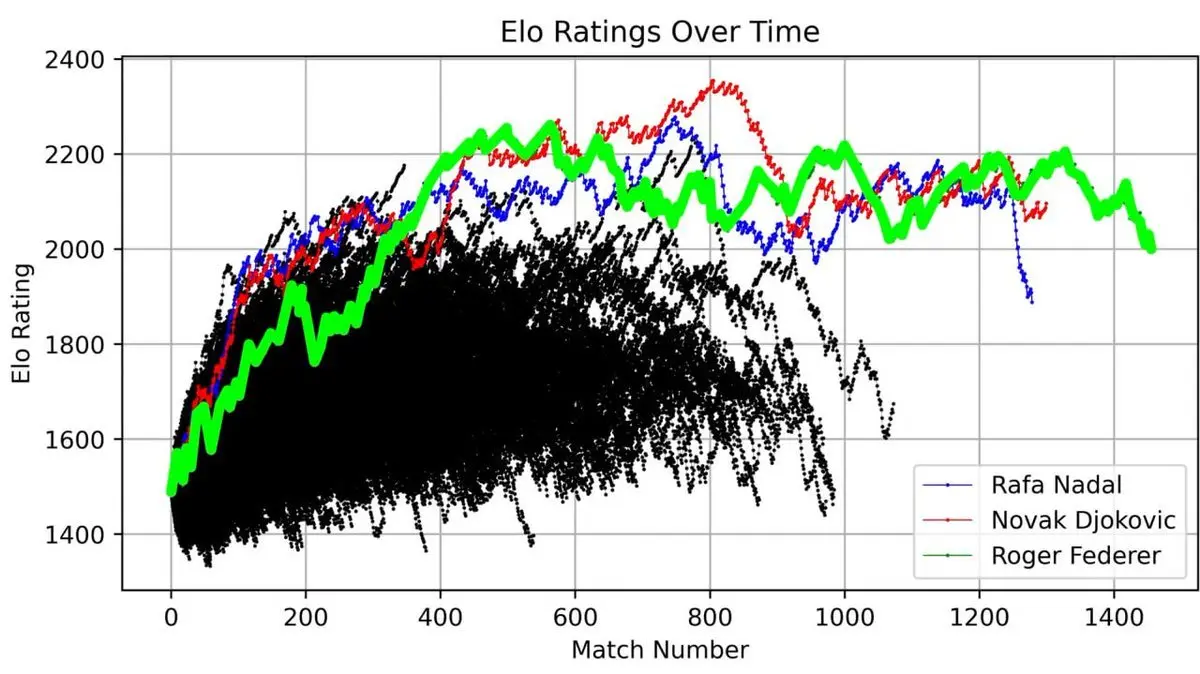
As três linhas se destacam, muito acima de todos os outros — Federer (verde), Nadal (azul), Djokovic (vermelho).
Os “Três Grandes” do Grand Slam não são só um título. Quando visualizamos 40 anos de dados, essa dominância fica matematicamente evidente.
Segundo seu sistema ELO personalizado, o atual número 1 do mundo é Jannik Sinner (2176 pontos), seguido por Djokovic (2096) e Alcaraz (2003).

Lembre-se de que Sinner está em primeiro lugar — isso será importante mais tarde.
Sexto passo: o piso do piso — o efeito do piso de jogo
O tipo de piso muda tudo no ténis:
- Argila: lento, com ressalto alto
- Relva: rápido, com ressalto baixo
- Hard court: intermediário
Um jogador que domina numa superfície pode ser completamente derrotado numa outra.
Por isso, criou classificações ELO específicas para cada tipo de piso: argila, relva, hard.
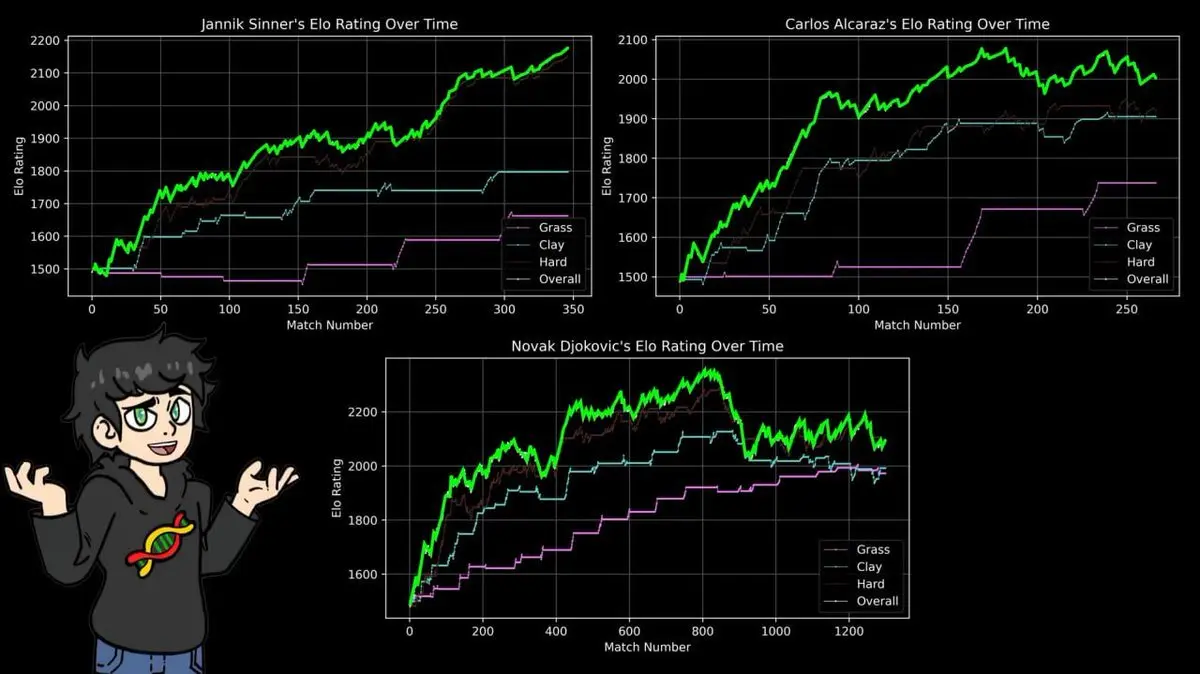
Os resultados confirmaram uma verdade bem conhecida entre os fãs: a pontuação máxima de Nadal na argila supera a de Federer na relva, que por sua vez supera a de Djokovic no hard court, e assim por diante.
14 títulos de Roland Garros, 112 vitórias e 4 derrotas na terra batida.
A fórmula ELO não se importa com narrativas ou fama, apenas registra vitórias e derrotas. E a conclusão bate exatamente com o que os 40 anos de notícias esportivas mostram.
Sétimo passo: enfrentando o teto
Com os dados prontos e o sistema ELO configurado, começou a treinar o classificador. Este passo mostrou bem a importância da escolha do algoritmo.
Árvore de decisão: 74% de acerto
Uma única árvore de decisão, treinada com todo o conjunto, atingiu 74% de precisão. Parece bom — até perceberes que só com a diferença de ELO, já se consegue 72%.
A árvore, baseada no sistema de pontuação que criou, pouco melhorou.
Florestas aleatórias: 76% de acerto
O problema da árvore única é a “alta variância” — ela é sensível aos dados de treino. A solução padrão é usar uma floresta aleatória: construir dezenas ou centenas de árvores, cada uma treinada com subconjuntos diferentes de dados e características, e votar na previsão final.

94 árvores diferentes votam em cada partida.

O resultado foi 76%. Melhorou, mas atingiu um teto. Nenhuma tentativa de ajustar hiperparâmetros, reengenharia de características ou manipulação de dados conseguiu ultrapassar 77%.
Oitavo passo: quebrar o teto
Depois, tentou o XGBoost — que chama de “versão esteróide da floresta aleatória”.
A diferença principal: enquanto a floresta faz árvores paralelas e tira a média, o XGBoost constrói árvores sequencialmente, cada uma corrigindo os erros das anteriores. Usa regularização para evitar overfitting, e mantém as árvores pequenas para não decorar os dados.
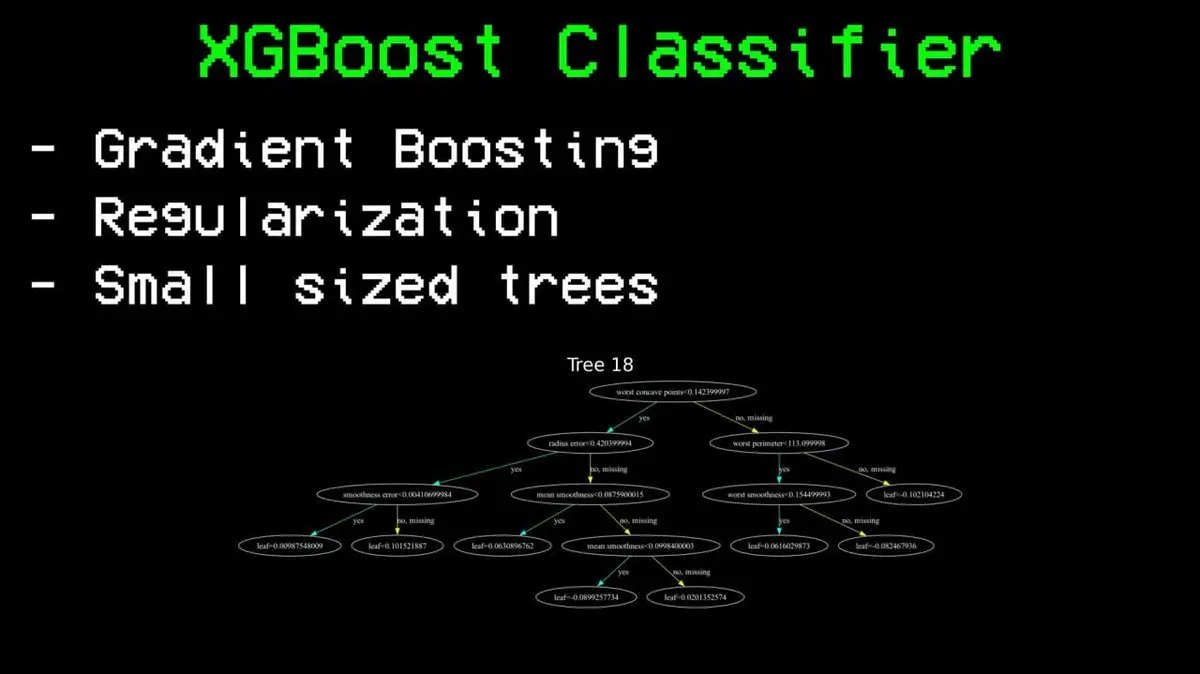
O resultado: 85% de acerto.
Um avanço enorme em relação ao teto de 76%. Com os mesmos dados, as mesmas características, a única mudança foi o algoritmo.
O XGBoost também confirmou que as três variáveis mais importantes são: diferença de ELO, diferença de ELO por superfície, e o ELO geral. Essa pontuação, inspirada no xadrez, é o melhor preditor entre as 81 variáveis.
Como comparação, treinou uma rede neural com os mesmos dados, atingindo 83%. Boa, mas ainda atrás do XGBoost. Para este conjunto, métodos baseados em árvores vencem.
Nono passo: o momento decisivo — Australian Open 2025
Tudo até aqui foi treinado com dados até dezembro de 2024.
O Australian Open de janeiro de 2025 não estava nos dados de treino, tornando-se um teste perfeito: o modelo realmente aprendeu as regras do ténis ou só memorizou padrões históricos?

Inseriu toda a tabela do torneio no modelo, para prever cada jogo.
Resultado: 99 previsões corretas em 116 jogos, erro em 17 — precisão de 85,3%.
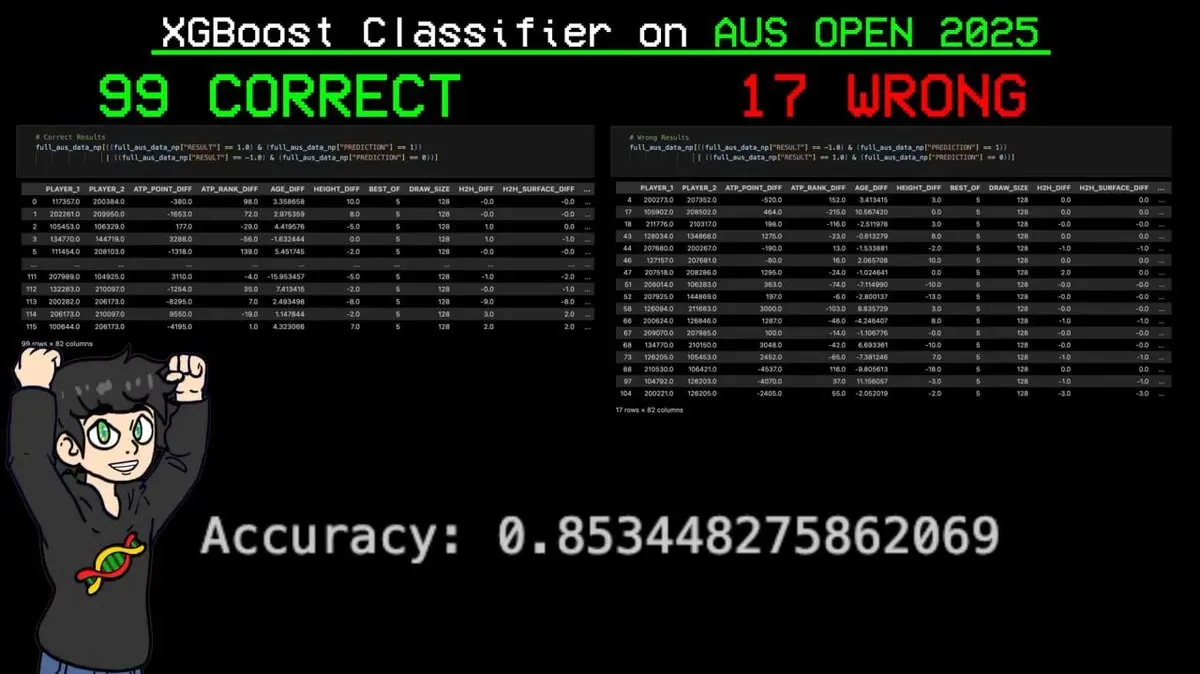
A previsão mais importante: o modelo previu com exatidão todas as vitórias de Sinner, o atual número 1 do mundo segundo o sistema ELO.
Antes mesmo da primeira bola, a IA já tinha previsto o campeão do Grand Slam.
Conclusão
Um homem, um portátil, sem dados proprietários, sem infraestrutura cara, sem equipe de pesquisa — criou um modelo de previsão de ténis profissional com 85% de acerto, e previu o campeão antes do início do torneio.
Os dados de ténis estão no GitHub, totalmente reproduzíveis.
Criar milagres nunca esteve tão ao alcance.
A verdadeira diferença não está nos recursos, mas na vontade de fazer.
