O avanço da inteligência artificial transforma a indústria global de semicondutores. Com o aumento da demanda por modelos de linguagem de grande escala, IA generativa e computação de alto desempenho, o volume de dados que os chips precisam processar cresce exponencialmente. Nesse contexto, as tecnologias de memória tradicionais atingem seus limites de largura de banda e eficiência energética, enquanto a HBM (High Bandwidth Memory)—que possibilita transferência de dados ultrarrápida—se consolida como um pilar da infraestrutura de IA.
No mercado global de HBM, a SK Hynix ocupa posição de destaque. Como uma das principais fabricantes de chips de memória do mundo, a SK Hynix não só possui vasta experiência em DRAM, como também assumiu a liderança no desenvolvimento e na produção em massa de produtos HBM. Com as GPUs de IA exigindo memórias cada vez mais rápidas, a SK Hynix se firmou como fornecedora-chave na cadeia de suprimentos de chips de memória para IA.
O que é HBM?
HBM (High Bandwidth Memory) é uma tecnologia de memória de alta largura de banda projetada especificamente para IA, computação de alto desempenho (HPC), data centers e processamento gráfico. Em comparação com a DRAM tradicional, a HBM oferece throughput de dados muito maior em um espaço muito menor.
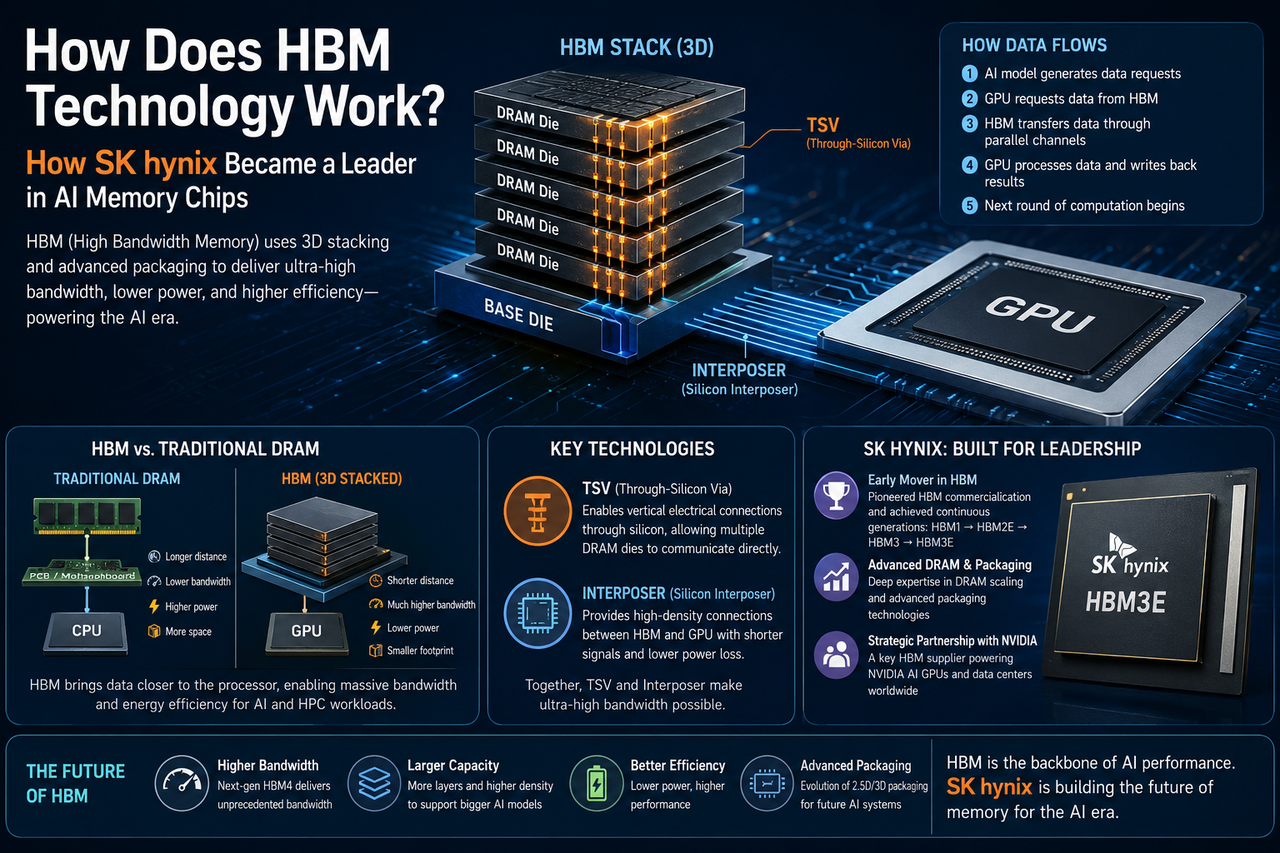
A principal inovação da HBM é sua arquitetura de empilhamento 3D, em que múltiplos chips DRAM são empilhados verticalmente e interconectados em alta velocidade pela tecnologia TSV (Through-Silicon Via). Como os dados percorrem distâncias menores, a HBM aumenta drasticamente a largura de banda e reduz o consumo de energia.
Por que a DRAM tradicional não atende às necessidades da IA
Por anos, a DRAM tradicional foi a solução de memória padrão para computadores e servidores. No entanto, as demandas de dados da era da IA superaram em muito as da computação convencional.
Durante o treinamento de modelos grandes, as GPUs precisam ler e escrever constantemente um número enorme de parâmetros. Se os dados não chegarem rápido o suficiente para alimentar a GPU, até os processadores mais potentes perdem ciclos esperando.
A DRAM tradicional enfrenta desafios:
| Desafio |
Desempenho da DRAM tradicional |
| Teto de largura de banda |
Throughput de dados limitado |
| Alto consumo de energia |
Caminhos de dados mais longos aumentam o consumo de energia |
| Grande área física |
Difícil de encaixar em implantações densas |
| Escalabilidade para IA |
Eficiência reduz em configurações com múltiplas GPUs |
Por isso a indústria recorreu a novas arquiteturas de memória mais adequadas à IA — e a HBM decolou.
Como funciona a tecnologia HBM
A ideia central da HBM: encurtar a distância que os dados percorrem e aumentar significativamente o número de canais de dados.
A DRAM tradicional se conecta ao processador pela placa-mãe. Já a HBM é empacotada diretamente ao lado da GPU. Múltiplos dies DRAM são empilhados verticalmente usando TSV, e um interposer de silício os conecta à GPU para comunicação de altíssima largura de banda.
O fluxo de dados funciona assim:
- Um modelo de IA executado na GPU gera um fluxo constante de solicitações de dados.
- A GPU envia comandos de leitura para a HBM.
- A HBM fornece dados de volta por vários canais paralelos em velocidade impressionante.
- Quando o processamento termina, a GPU grava os resultados de volta na memória.
- O próximo ciclo de processamento começa imediatamente.
Esse design minimiza a latência do movimento de dados e melhora drasticamente a eficiência do treinamento de IA.
HBM vs. DRAM tradicional: diferenças estruturais
| Dimensão |
HBM |
DRAM tradicional |
| Arquitetura do chip |
Empilhamento 3D |
Layout planar |
| Interconexão de dados |
TSV + Interposer |
Trilhas de PCB |
| Largura de banda |
Ultra-alta |
Moderada |
| Consumo de energia |
Menor |
Maior |
| Principais casos de uso |
IA, GPU, HPC |
PCs, servidores |
Por que TSV e interposer são importantes
TSV (Through-Silicon Via) é a tecnologia que viabiliza o empilhamento 3D da HBM. Ela cria canais verticais através do chip, permitindo que as camadas de memória empilhadas se comuniquem diretamente entre si. O interposer (interposer de silício) serve como ponte de conexão entre a GPU e a HBM, fornecendo caminhos de dados muito mais densos e menor perda de sinal do que as trilhas tradicionais da placa-mãe.
Juntas, essas duas tecnologias formam a espinha dorsal da arquitetura HBM e são as principais razões para ela atingir largura de banda tão extrema.
O papel da HBM no treinamento de IA
Os modelos modernos de IA contêm bilhões ou até trilhões de parâmetros. Cada execução de treinamento exige a leitura de vastos conjuntos de dados.
Se a GPU processar mais rápido do que os dados chegam, o sistema sofre com poder computacional ocioso. O trabalho da HBM é manter o pipeline de dados cheio, garantindo que a GPU opere com eficiência máxima.
Na inferência de IA, a HBM é igualmente crítica. O acesso rápido à memória acelera os tempos de resposta e melhora o desempenho do modelo. Por isso a HBM se tornou uma parte indispensável do design de chips de IA.
Como a SK Hynix se tornou líder em HBM
A SK Hynix tem raízes profundas na tecnologia DRAM, que lançaram as bases para seus avanços em HBM.
A empresa foi uma das primeiras a comercializar a HBM. Do HBM1 ao HBM3E, a SK Hynix expandiu continuamente os limites de largura de banda, capacidade, eficiência energética e empacotamento avançado.

Antes da febre da IA, o mercado de HBM era relativamente nichado. No entanto, a SK Hynix continuou investindo em P&D. Quando a IA generativa e os modelos grandes dispararam a demanda, a empresa já tinha tecnologia madura e capacidade de produção prontas.
Esse posicionamento estratégico de longo prazo deu à SK Hynix uma vantagem competitiva formidável.
SK Hynix e NVIDIA: uma parceria estratégica
As GPUs de IA são o maior mercado de aplicação para HBM, e a NVIDIA é um grande player no espaço de chips de IA.
As GPUs de IA de ponta atuais exigem subsistemas de memória massivos e de alta largura de banda. A HBM se tornou o padrão para GPUs de alto desempenho, e a SK Hynix é uma fornecedora chave de HBM.
Essa relação permite que a SK Hynix desempenhe um papel central na construção da infraestrutura de IA — e fortalece sua importância estratégica na cadeia global de suprimentos de semicondutores.
O futuro da HBM
À medida que os modelos de IA continuam a crescer, a tecnologia HBM evolui.
Principais tendências no horizonte:
| Direção tecnológica |
Objetivo |
| HBM4 |
Largura de banda e capacidade ainda maiores |
| Mais camadas de empilhamento |
Maior densidade de memória |
| Empacotamento avançado |
Menor latência e consumo de energia |
| Memória otimizada para IA |
Melhor eficiência de treinamento |
| Integração Chiplet |
Escalabilidade aprimorada do sistema |
No futuro, os ganhos de desempenho em chips de IA dependerão não apenas da GPU em si, mas cada vez mais da inovação em memória.
HBM vs. GDDR: qual é a diferença?
Tanto HBM quanto GDDR são memórias de alto desempenho, mas projetadas para funções diferentes.
GDDR é voltada para placas gráficas de consumo, aumentando a velocidade por meio de frequências de clock mais altas. Já a HBM atinge seu desempenho por meio de um barramento ultra-largo e empilhamento vertical, oferecendo maior largura de banda e menor consumo de energia. Em treinamento de IA, HPC e ambientes de data center, a HBM leva clara vantagem.
Resumo
A HBM é uma das tecnologias de memória mais importantes da era da IA. Por meio de empilhamento 3D, TSV e interposer de silício, ela oferece largura de banda que supera em muito a DRAM tradicional. À medida que o treinamento de modelos grandes e a computação de alto desempenho exigem mais, a HBM se torna essencial para GPUs de IA e infraestrutura de data centers.
Graças a décadas de expertise em DRAM, habilidades avançadas de empacotamento e investimento incansável em HBM, a SK Hynix se consolidou como líder global. De chips de IA a data centers, de GPUs a supercomputadores, a HBM impulsiona o crescimento da computação de IA — e a SK Hynix está no centro dessa cadeia de suprimentos crítica.
Perguntas frequentes
Por que a HBM é melhor para IA do que a DRAM tradicional?
A HBM oferece largura de banda muito maior, latência menor e consumo de energia menor. O treinamento de modelos de IA lê constantemente conjuntos de dados enormes, então a HBM atende muito melhor às necessidades de memória da GPU.
O que é a tecnologia TSV?
TSV (Through-Silicon Via) cria conexões elétricas verticais através de chips empilhados. A HBM usa TSV para alcançar empacotamento 3D denso.
Qual é a diferença entre HBM e GDDR?
GDDR é projetada para renderização gráfica; HBM é construída para IA, HPC e data centers. A HBM normalmente oferece largura de banda e eficiência energética superiores.
Por que a SK Hynix lidera o mercado de HBM?
A SK Hynix investiu cedo em HBM e tem profunda expertise em fabricação de DRAM e empacotamento avançado. Quando a demanda por IA explodiu, a empresa já tinha produtos maduros e produção pronta para escalar.
O que o HBM4 vai mudar?
Espera-se que o HBM4 amplie ainda mais a largura de banda, a capacidade e a eficiência energética, suportando cargas de treinamento de IA maiores. À medida que a computação de IA continua a escalar, o HBM4 deve se tornar uma solução de memória importante para plataformas de alto desempenho da próxima geração.









