Outil AI CanIRun.ai peut détecter automatiquement via le navigateur la configuration matérielle de l’utilisateur, permettant d’estimer quels modèles LLM peuvent être exécutés et leur vitesse d’inférence. Les utilisateurs intéressés peuvent l’essayer pour mieux comprendre.
(Précédent résumé : Clawdbot, une AI maisonnette qui rend le Mac mini en rupture de stock, 24/7)
(Complément d’information : Ne suivez pas aveuglément OpenClaw, la petite crevette AI est puissante mais pas forcément adaptée à vous)
Sommaire
Toggle
- Les petits défauts de Canirun.ai
- La solution en ligne de commande llmfit arrive
- Ce que la communauté souhaite le plus
Souhaitez-vous installer un grand modèle de langage (LLM) localement ? La première question que se pose souvent un débutant est : Quel modèle mon ordinateur peut-il faire tourner ? Cet article présente un outil récemment discuté dans la communauté Hacker News : CanIRun.ai.
CanIRun.ai est un outil web simple : il suffit d’ouvrir le navigateur, et il détecte automatiquement via l’API WebGPU votre modèle de GPU et sa mémoire, puis, en fonction du nombre de paramètres, du niveau de quantification (Q4_K_M, Q8_0, F16, etc.) et de la bande passante mémoire, il estime la faisabilité et la vitesse d’inférence (tokens/sec) pour chaque modèle, en affichant une note allant de S à F.
Il couvre tout, du modèle ultra-léger de 0,8 milliard de paramètres, jusqu’aux géants MoE (Mixture of Experts, architecture à experts multiples) de 1 trillion de paramètres, avec des sources comme llama.cpp, Ollama et LM Studio, parmi les principaux outils d’inférence locale.
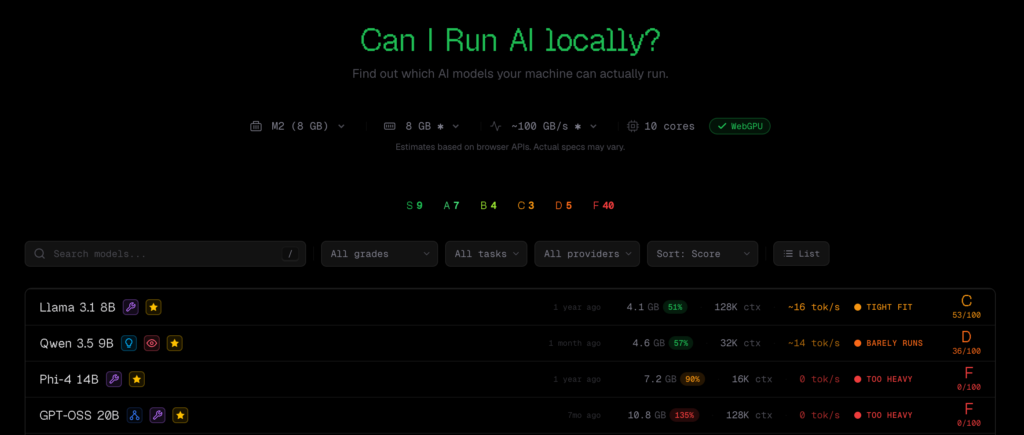
Les petits défauts de CanIRun.ai
Bien que le concept de l’outil soit salué par la communauté, il présente aussi quelques critiques. Principalement deux points : une couverture matérielle incomplète, et un écart entre estimation et résultats réels.
Le manque de liste matérielle est le problème le plus souvent mentionné. Les GPU comme RTX Pro 6000, RTX 5060 Ti 16GB, ou certains GPU portables ne figurent pas dans la liste. Pour les puces Apple, bien qu’elles soient listées, la configuration maximale indiquée est de 192GB de mémoire, alors que le M3 Ultra peut supporter jusqu’à 512GB.
Concernant l’écart d’estimation, certains utilisateurs ont constaté que les résultats réels ne correspondent pas toujours à ce que CanIRun.ai indique. Ces cas où le modèle peut tourner mais le site dit non, reviennent fréquemment dans les discussions, poussant certains à ne plus se fier à ses résultats.
Malgré ces améliorations possibles, pour un débutant, l’outil reste un moyen rapide de vérifier la compatibilité de son matériel.
La solution en ligne de commande llmfit arrive
Par ailleurs, la communauté recommande un outil alternatif : llmfit. C’est un programme en ligne de commande qui peut directement interroger les outils système (comme nvidia-smi) pour obtenir des informations précises sur le GPU, sans dépendre de l’API WebGPU. Beaucoup le trouvent plus pratique et précis que la version web.
Cependant, llmfit soulève un autre sujet : certains utilisateurs sont surpris qu’il puisse identifier précisément le modèle de GPU sans demander d’autorisations explicites. Cela a suscité une sensibilité sur la vie privée et la reconnaissance de l’empreinte du navigateur : si un site peut détecter votre carte graphique via WebGPU, comment cette donnée sera-t-elle utilisée ?
Un utilisateur suggère que cette fonctionnalité serait idéale si elle était intégrée directement dans Ollama, permettant aux utilisateurs de filtrer automatiquement les modèles compatibles depuis la ligne de commande, sans recherche manuelle.
Ce que la communauté souhaite le plus
Selon les retours, la limite principale de CanIRun.ai n’est pas seulement la précision de l’estimation, mais aussi la dimension d’évaluation trop limitée. Les utilisateurs veulent surtout savoir : sur mon matériel, quel modèle offre la meilleure qualité tout en étant suffisamment rapide ? Actuellement, l’outil ne répond qu’à la question : « Peut-il tourner ? », sans pouvoir dire si la performance est satisfaisante.
La communauté souhaite que l’avenir intègre une évaluation des capacités du modèle, combinée à une estimation matérielle, pour offrir une sélection plus complète. D’autres améliorations techniques envisagées incluent : l’intégration de stratégies de partage de mémoire CPU (pour que les GPU avec peu de mémoire puissent utiliser la mémoire système), le support du déchargement du cache KV, et la correction de la logique de calcul pour les modèles MoE.
En résumé, la direction de l’outil est bonne, et la demande du marché existe : pour le grand public, le seuil d’entrée pour l’IA locale reste élevé. Pouvoir rapidement déterminer « Qu’est-ce que mon ordinateur peut faire tourner ? » est une nécessité. CanIRun.ai répond à ce besoin, mais doit encore être affiné.
Avertissement : Les informations contenues dans cette page peuvent provenir de tiers et ne représentent pas les points de vue ou les opinions de Gate. Le contenu de cette page est fourni à titre de référence uniquement et ne constitue pas un conseil financier, d'investissement ou juridique. Gate ne garantit pas l'exactitude ou l'exhaustivité des informations et n'est pas responsable des pertes résultant de l'utilisation de ces informations. Les investissements en actifs virtuels comportent des risques élevés et sont soumis à une forte volatilité des prix. Vous pouvez perdre la totalité du capital investi. Veuillez comprendre pleinement les risques pertinents et prendre des décisions prudentes en fonction de votre propre situation financière et de votre tolérance au risque. Pour plus de détails, veuillez consulter l'
avertissement.