En la industria de la IA actual, el etiquetado de datos representa una parte relevante de los costes de desarrollo. Sin embargo, las plataformas centralizadas tradicionales suelen enfrentarse a silos de datos, ineficiencia y una distribución poco transparente de la rentabilidad. Tagger quiere solucionar estos problemas con una arquitectura descentralizada, haciendo la producción de datos más abierta, eficiente y verificable.
Desde la perspectiva de blockchain y los activos digitales, el valor central de Tagger está en transformar los “datos” en activos que pueden validarse y negociarse, y en usar incentivos con tokens para impulsar la producción colaborativa a nivel global. Así, los datos dejan de ser solo un recurso para el entrenamiento de IA y se convierten en una pieza clave dentro del ecosistema económico de Web3.
Descripción general del mecanismo de etiquetado de datos de Tagger (TAG)
El mecanismo de etiquetado de datos de Tagger funciona como un “sistema descentralizado de producción de datos”. Su meta principal es convertir datos en bruto en activos estructurados, listos para modelos de IA. El sistema se articula en cuatro etapas: recopilación de datos, etiquetado, validación y entrega, creando una cadena integral de procesamiento de datos.
El mecanismo de Tagger divide la producción de datos en módulos independientes: recopilación, etiquetado y validación. Cada módulo lo ejecutan diferentes participantes de forma colaborativa, evitando que una sola entidad tenga el control total del proceso. Este enfoque distribuido no solo mejora la eficiencia, sino que también refuerza la resiliencia del sistema.
Tagger integra herramientas impulsadas por IA (como AI Copilot) en el proceso de etiquetado, permitiendo que cualquier usuario pueda abordar tareas complejas. Este modelo de “colaboración humano-máquina” reduce significativamente la barrera de entrada al etiquetado profesional de datos, atrae a más participantes y acelera el crecimiento del suministro de datos.
En esencia, el mecanismo de etiquetado de Tagger va mucho más allá del crowdsourcing tradicional. Es un sistema completo que combina validación basada en blockchain, asistencia de IA y mecanismos de incentivos, formando la nueva infraestructura para la producción de datos de IA.
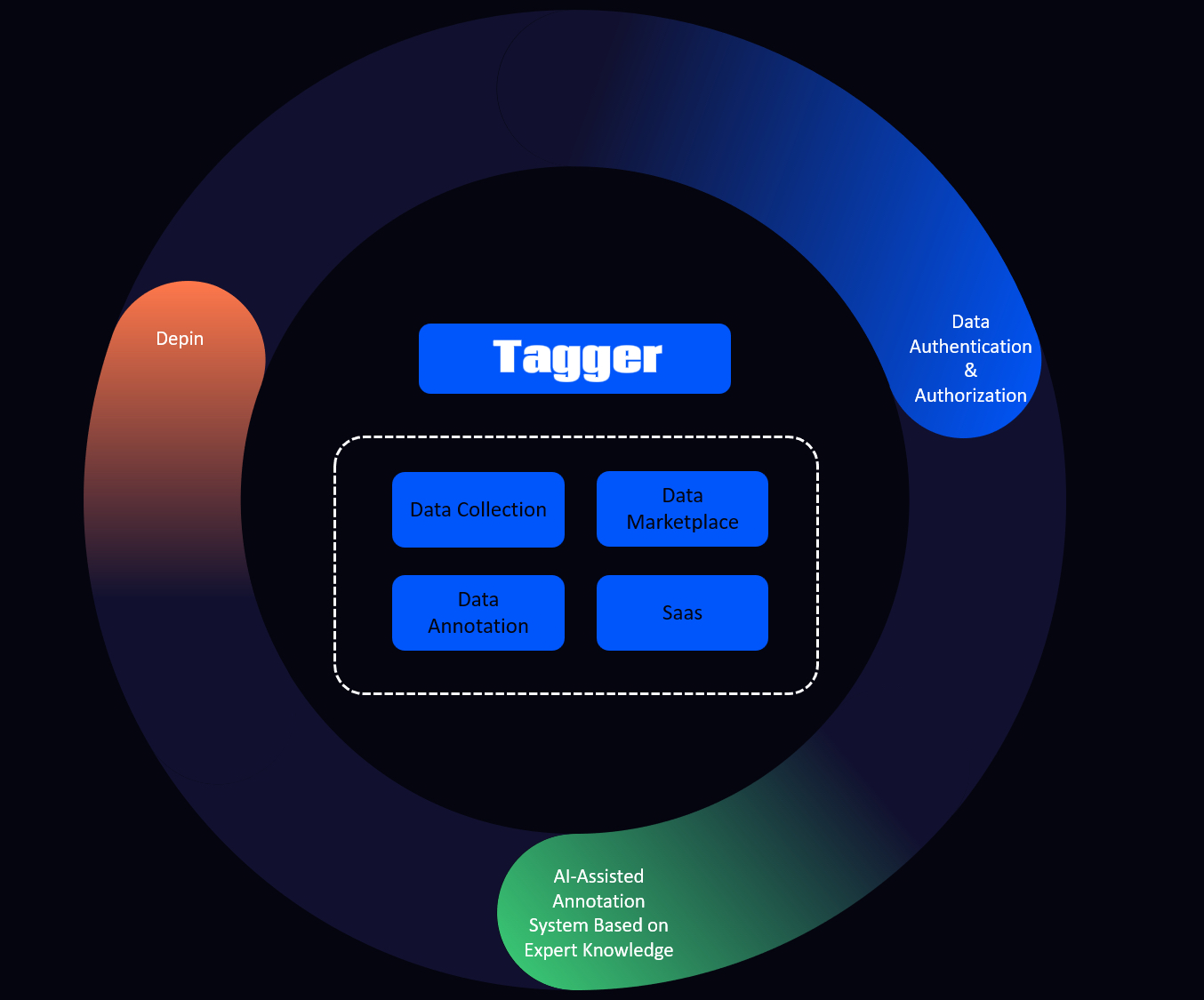
Fuente: tagger.pro
Cómo Tagger (TAG) distribuye tareas de datos: etiquetado colaborativo y asignación de tareas
En la red de Tagger, la distribución de tareas de datos es el vínculo fundamental entre la demanda y la oferta. Los solicitantes de datos, como desarrolladores de IA o empresas, pueden publicar tareas de etiquetado en la plataforma, definiendo reglas, presupuestos y requisitos de calidad. El sistema divide estas tareas en subtareas y las asigna a distintos participantes.
La asignación de tareas se basa en algoritmos inteligentes de coincidencia. La plataforma tiene en cuenta el tipo de tarea, la categoría de datos y las capacidades de los participantes para asignar cada tarea al nodo más adecuado. Por ejemplo, las tareas de etiquetado de imágenes se asignan primero a etiquetadores con experiencia relevante, lo que mejora la eficiencia y la precisión.
Tagger también aprovecha el modelo de crowdsourcing para escalar rápidamente. A diferencia de los equipos de outsourcing tradicionales, una red descentralizada puede movilizar a usuarios globales al mismo tiempo, acelerando de forma significativa el procesamiento de datos. Esto resulta especialmente útil para proyectos de IA que requieren manejar grandes volúmenes de datos.
Durante la distribución, los Contratos inteligentes pueden automatizar la ejecución de tareas y los pagos. Cuando una tarea se completa y se valida, el sistema emite automáticamente las recompensas, reduciendo la intervención manual y maximizando la eficiencia.
Cómo Tagger (TAG) valida los resultados del etiquetado: validación de datos y control de calidad
La calidad de los datos es esencial para el entrenamiento efectivo de la IA, por eso Tagger utiliza un sistema de validación multinivel tras el etiquetado, garantizando precisión y consistencia. En vez de depender de un solo nodo, la validación es colaborativa.
Primero, el sistema emplea consenso de múltiples etiquetadores: los mismos datos son etiquetados de forma independiente por varios participantes y solo se aceptan los resultados consistentes o similares. Así se minimiza el impacto de errores individuales.
Después, Tagger incorpora herramientas de verificación con IA para controles automáticos de calidad. Por ejemplo, los modelos comprueban si el etiquetado es lógico o si hay errores evidentes, aumentando la eficiencia del control de calidad.
Para datos de alto valor, se pueden introducir mecanismos de reputación y staking. Los resultados de nodos con buena reputación tienen más peso, mientras que las acciones de baja calidad pueden ser penalizadas. Este diseño motiva a los participantes a mantener altos estándares a través de recompensas económicas.
Cómo Tagger (TAG) utiliza los datos etiquetados: entrenamiento de modelos de IA y aplicaciones de datos
Después del etiquetado y la validación, los datos pasan al uso práctico, principalmente el entrenamiento y la optimización de modelos de IA. Los datos etiquetados de calidad pueden mejorar notablemente la precisión y la capacidad de generalización de los modelos, lo que convierte esta etapa en un eje central del valor del sistema.
En machine learning, los datos etiquetados son imprescindibles para el aprendizaje supervisado. Por ejemplo, los modelos de clasificación de imágenes requieren grandes volúmenes de datos etiquetados, mientras los sistemas de reconocimiento de voz necesitan transcripciones precisas. Los datos de Tagger pueden usarse directamente en estos casos.
Además del entrenamiento, los datos etiquetados también sirven para evaluar y optimizar modelos. Las pruebas con datos etiquetados ayudan a medir el rendimiento del modelo y a ajustar parámetros, por lo que los datos de Tagger son un recurso clave durante todo el ciclo de vida de la IA.
Tagger también facilita el comercio y la aprobación de datos, permitiendo que los datos circulen entre distintas aplicaciones. Así, los datos dejan de ser un recurso de un solo uso para convertirse en un activo reutilizable, aumentando su valor económico.
Análisis de rendimiento y eficiencia del mecanismo de etiquetado de Tagger (TAG)
La principal fortaleza de Tagger es la escalabilidad. Su red descentralizada puede aumentar dinámicamente la participación según la demanda de procesamiento de datos, lo que la hace ideal para proyectos de IA a gran escala.
Las herramientas asistidas por IA potencian aún más la eficiencia. El pre-etiquetado y la verificación automática reducen el trabajo manual, permitiendo que los etiquetadores se centren en decisiones clave y aumentando la productividad.
Sin embargo, la descentralización puede generar cierta latencia. La validación multiparte mejora la calidad, pero puede alargar los tiempos de procesamiento, por lo que es necesario equilibrar eficiencia y precisión.
En definitiva, el rendimiento de Tagger depende de sus algoritmos de asignación de tareas, mecanismos de validación y el tamaño de la red. A medida que la red crece, se espera que la eficiencia siga aumentando.
Ventajas y posibles limitaciones del mecanismo de etiquetado de Tagger (TAG)
Las ventajas principales de Tagger son la apertura y los incentivos, ya que permite la participación global en la producción de datos y una rápida expansión de la oferta. La validación y trazabilidad con blockchain también refuerzan la credibilidad de los datos.
Las herramientas de etiquetado asistidas por IA reducen la barrera profesional, permitiendo que usuarios sin experiencia aporten datos de calidad, algo esencial para combatir la escasez de datos.
Aun así, existen retos. Las diferencias de habilidad entre participantes pueden afectar la consistencia de los datos, y el control de calidad en entornos descentralizados es más complejo. Además, la coordinación y gestión de tareas implica costes superiores a los de sistemas centralizados.
Un error habitual es pensar que Tagger es solo una “plataforma de crowdsourcing”. En realidad, es una economía de datos integral: producción, validación, circulación y aprobación, con una complejidad y potencial muy superiores a los modelos tradicionales.
Resumen
Tagger (TAG) combina blockchain, IA y crowdsourcing para crear una red descentralizada de etiquetado y validación de datos. Su principal innovación es distribuir la producción de datos a escala global, garantizando la calidad mediante sistemas sólidos de validación e incentivos.
Este modelo no solo mejora la eficiencia en la producción de datos, sino que también ofrece un suministro sostenible de datos para el desarrollo de la IA. Ahora que los datos son la base de la IA, infraestructuras descentralizadas como Tagger se perfilan como una pieza clave para la integración de Web3 e IA.
Preguntas frecuentes
¿Cómo garantiza Tagger (TAG) la calidad del etiquetado de datos?
Combinando consenso de múltiples etiquetadores, verificación con IA y un sistema de reputación para asegurar la precisión de los datos.
¿En qué se diferencia el etiquetado de datos de Tagger respecto a plataformas tradicionales?
Tagger utiliza un modelo de crowdsourcing descentralizado con validación e incentivos basados en blockchain, a diferencia de las plataformas tradicionales controladas por entidades centralizadas.
¿Qué función cumple TAG en el proceso de etiquetado de datos?
TAG se usa para pagar las comisiones de las tareas e incentivar a los participantes; es el motor principal de la red de producción de datos.
¿Cuáles son los principales escenarios de aplicación de los datos de Tagger?
Principalmente entrenamiento de modelos de IA, análisis de datos y comercio de datos.
¿Tagger es adecuado para el procesamiento de datos a gran escala?
Sí, su arquitectura descentralizada permite escalar de forma dinámica, por lo que es ideal para tareas de datos a gran escala.









